





















Introduction
Poor retrieval in AI Agents and RAG systems cause hallucinations, missed events, and confident answers from incomplete data. Manual relevance labeling was the traditional fix, but at $100 per hour for domain experts and thousands of queries running daily across multi-step agent workflows, it doesn't scale.
Modern teams are replacing it with automated AI agent evaluation pipelines that use LLMs as evaluators, synthetic datasets to benchmark recall, and structured retrieval metrics to catch regressions.
To ground these pipelines in reliable data, teams rely on structured retrieval APIs that generates citable, deduplicated datasets and measures recall across the open web without maintaining custom scraping infrastructure.
In this article, we will cover how to build an automated AI agent evaluation framework, covering metrics, LLM-as-a-judge systems, and common scaling pitfalls that undermine evaluation.
Why is AI search evaluation more complex than traditional search?
AI evaluation is more complex than classic search evaluation because it combines retrieval with generation and decision-making.
Traditional search evaluation relies on metrics like click-through rates or MRR, and MAP. If a user searches for a term and clicks the first link, the traditional search engine registers the search as a success.
But AI evaluation has to overcome the following issues:
- Ambiguous relevance: A document can be topically related but factually useless for the agent's specific task.
- Changing query intent: The same query issued at different points in a multi-step workflow requires different results.
- Freshness requirements: Stale data yields confident answers based on outdated facts, with no visible signal that anything is wrong.
Hallucinated citations: The agent produces a fluent response pointing to fabricated or non-existent sources.
What are the key AI agent evaluation metrics for web search?
An agent's reasoning is only as good as the context it retrieves. The relevant AI agent evaluation metrics to track are:
How to build a scalable infrastructure for AI search evaluation?
Scalable infrastructure for AI search evaluation requires a unified pipeline that connects real-time retrieval, automated scoring models, and observability traces into a continuous feedback loop. Most teams fail because they treat evaluation as a manual checkpoint.
Building a modern AI agent evaluation framework involves four layers: ingestion, observation, evaluation, and iteration.
The ingestion and retrieval layer
The ingestion and retrieval layer is a gateway for grounding agentic workflow. The first step is moving away from custom scraping and raw HTML parsing. Maintaining scrapers for thousands of domains is a major operational drain. Instead, teams use web search APIs that return structured, machine-readable data.
The CatchAll provides a foundational layer of structured, real-time data for scalable AI evaluation and stable benchmarking. It enables developers to generate consistent datasets. Teams can isolate reasoning failures from retrieval noise and establish consistent baseline benchmarks by supplying a clean JSON context into the evaluation pipeline.
The observability and tracing layer
To evaluate an agent, you must see its reasoning trajectory. Platforms like Langfuse, Arize Phoenix, and W&B Weave provide span-level and trace-level visibility.
- Span-level evaluation: Targets individual steps, such as a single search query or tool call, to isolate where the reasoning chain broke.
- Trace-level evaluation: Examines the complete operation chain to judge whether the agent reached the correct final result.
Retrieved results and traces feed into an evaluation queue that runs deterministic checks and LLM-as-a-judge scoring in parallel. Outputs land in an analytics dashboard where metric time series like recall, freshness, duplication rate, and hallucination rate are tracked across runs.
How to use LLM-as-a-judge systems for retrieval evaluation?
LLMs are used to automate relevance scoring and retrieval evaluation by serving as judges that grade outputs against natural-language rubrics. A judge model reads the retrieved search results and the user's query to determine semantic relevance and factual grounding.
Common use cases for LLM judges in AI agent evaluation include:
- Relevance grading: The judge assesses if a retrieved document holds information pertinent to a specific query. A sample prompt might ask the model to provide a score from 0 (irrelevant) to 2 (highly relevant) and justify its reasoning.
- Pairwise ranking: Instead of scoring one output, the judge chooses the better of two versions. This method removes positional bias and yields more stable rankings across evaluation cycles.
- Faithfulness scoring: Judge extracts every claim from the agent's answer and checks if it is explicitly supported by the retrieved context.
- Citation verification: The judge ensures that every citation within an agent's report accurately supports its corresponding claim.
- Semantic similarity evaluation: A judge identifies near-duplicate documents that are semantically identical despite having different surface-level text.
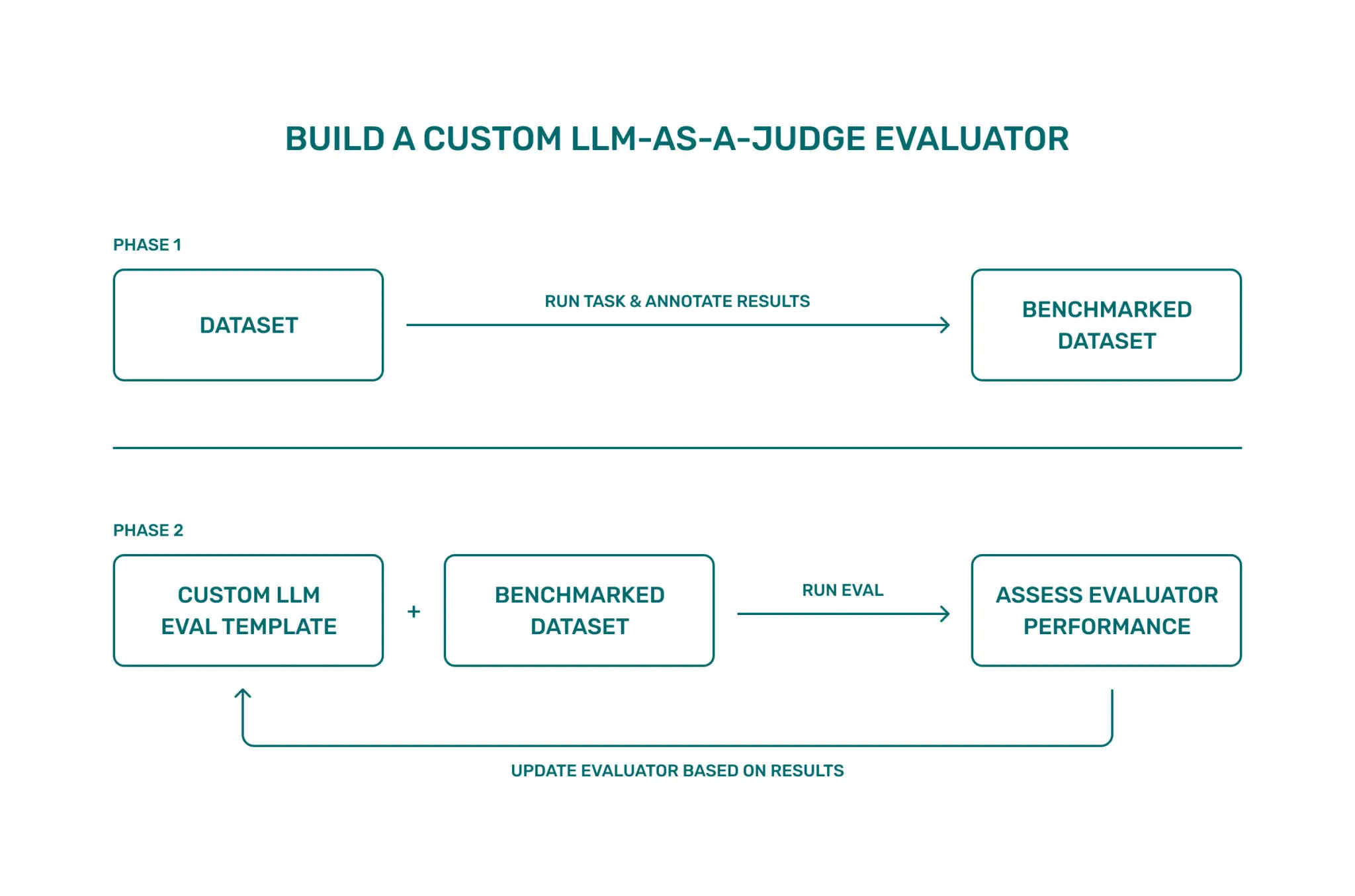
Synthetic benchmarking and automated dataset generation
Synthetic benchmarking is the automated generation of test queries, relevance labels, and adversarial cases to evaluate AI agents without relying on human data.
AI agent evaluation methods may use the following automated dataset generation techniques:
- Synthetic query generation: An LLM is given a document (seed topics) and asked to generate 10 questions that this document answers perfectly. This creates a ground-truth Golden Set for measuring retrieval recall.
- Query expansion and adversarial cases: Teams use LLMs to take a standard query and rewrite it to be ambiguous, misspelled, or intentionally misleading. This tests the robustness of the agent's query planning logic.
- Automatic labeling: Label synthetic queries using a two-stage process. First, retrieve results from a high-recall source, and second, run LLM judges to score relevance. The output is a labeled dataset without human annotation. Accuracy is lower than human labels but sufficient for regression testing and relative comparison between retrieval systems.
To build high-quality synthetic benchmarks, you need a high-quality knowledge source. If the input data is messy, the synthetic queries will be nonsensical. Using search APIs, such as the CatchAll API, is valuable for building evaluation datasets and ensuring that the agent is tested against structured, factual, and real-time records.
CatchAll processes 50,000+ pages per job, validates each result before returning it, and returns broad structured coverage without requiring custom scraping infrastructure. In fact, it achieved an F1 score of 0.705 in the Q1 2026 benchmark across 32 event-detection queries.
Why do deduplication and result normalization improve AI agent evaluation?
Retrieval systems often return redundant chunks of information, which waste token space and degrade the reasoning quality of AI agents. If an agent retrieves five different URLs that all contain the same syndicated news article, it consumes 5x more tokens and risks "attention decay".
Furthermore, duplicate content creates confusion for AI evaluation judges who need to know which version of a page to trust as the primary source.
Teams implement several deduplication strategies as part of their AI agent evaluation framework:
- URL normalization: Standardizing protocols, trailing slashes, and removing tracking parameters before fetching content.
- Canonicalization: Using <link rel="canonical"> tags to identify the authoritative version of a page among multiple mirrors.
- Content hashing: Comparing MD5 or SHA-256 hashes of extracted text to catch exact duplicates across different URLs.
- Semantic deduplication: Using vector embeddings and cosine similarity to identify articles that discuss the same event in different words.
- Clustering: Grouping related events to ensure the agent retrieves a diverse set of perspectives rather than the same fact repeated ten times.
Common mistakes teams make when evaluating AI search
The most common mistake is testing by vibe, releasing an agent because a developer chatted with it, and it seemed fine. Without a systematic AI agent evaluation framework, agents often fail on edge cases and hallucinate under the pressure of messy production data.
Here are the common mistakes, their failure modes, and mitigation strategies.
Focusing only on generated answers: Disaggregated evaluation is necessary to distinguish between a dumb model and a blind retriever.
- Problem: Testing only the final output ignores the RAG triad (Context Relevance, Faithfulness, Answer Relevance).
- Failure Mode: A correct answer might mask broken retrieval, or a hallucination might be blamed on the model when the retriever actually provided zero relevant facts.
- Mitigation: Use span-level AI agent evaluation metrics to track exactly which search results were used in the final answer and evaluate the retriever independently using precision and recall.
Ignoring retrieval recall: AI agents cannot synthesize facts that were never retrieved from the open web.
- Problem: Many teams measure only precision (how many results were relevant) while ignoring the observable universe of missed events.
- Failure Mode: The agent produces "I don't know" responses or incomplete reports, even when the required information is available online.
- Mitigation: Use a recall-first infrastructure like CatchAll to ensure the context window is populated with the long-tail facts needed for comprehensive research.
Neglecting freshness and temporal drift: Static datasets cannot evaluate an agent's ability to handle breaking news or evolving facts.
- Problem: Skipping freshness checks means the agent is never tested on "index drift" or new regulatory events.
- Failure Mode: The agent hallucinates outdated pricing, dead CEOs, or deprecated policies because the eval set is six months old.
- Mitigation: Use continuous-awareness monitors and time-series search APIs that enable real-time benchmarking against today's live web index.
Overlooking multilingual and diverse sources: The open web is not English-only, and relying on top-tier domains alone creates massive data gaps.
- Problem: Ignoring multilingual retrieval and small local publishers limits the agent's ground truth.
- Failure Mode: Missing local signals in global market monitoring or failing to detect regional supply chain risks.
- Mitigation: Integrate search layers that support 100+ countries and use semantic deduplication to normalize facts across different languages.
Summary
Effective AI agent evaluation for web search measures retrieval and generation independently, runs evaluations continuously, and catches regressions before they reach users. The right AI agent evaluation methods combine recall-first retrieval infrastructure, LLM-as-a-judge scoring, synthetic benchmarking, and deduplication pipelines. Each addresses a distinct failure mode that traditional search metrics were never built to catch.
FAQs
Q1: What is the best tool for AI agent evaluation?
No single tool covers everything, most production teams combine a structured retrieval API like CatchAll for recall-oriented data collection, an LLM-as-a-judge pipeline for automated relevance scoring, and an observability platform for trace-level monitoring. The right stack depends on whether your bottleneck is retrieval coverage, generation faithfulness, or workflow-level reasoning.
Q2: What makes a good AI agent evaluation system?
A good system measures retrieval and generation independently, runs continuously rather than on demand, and alerts on regressions before users notice them. It covers recall, freshness, faithfulness, and hallucination rate, along with final answer quality.
Q3: Which tools make AI agent evaluation easier?
For retrieval benchmarking, managed APIs that return validated structured JSON, like CatchAll, cut dataset preparation time from weeks to hours. For scoring and tracing, RAGAS and DeepEval handle LLM-based evaluation, while Langfuse and LangSmith provide the workflow visibility needed to isolate where failures originate.
Q4: What are AI agent evaluation frameworks?
AI agent evaluation frameworks are structured systems for measuring agent performance across retrieval, reasoning, and output quality, covering metrics such as recall, faithfulness, and the hallucination rate.
Get started with CatchAll for recall-first web search evaluation. Start with 2,000 free credits at platform.newscatcherapi.com — enough to benchmark retrieval quality across several query types without any scraping infrastructure.
- Documentation: newscatcherapi.com/docs/web-search-api/get-started/introduction
- Questions? Email us at support@newscatcherapi.com



.png)






































