You start with a proximity query such as: NEAR("Amazon", "Alexa", 10). This returns every article where both terms appear within 10 words of each other. The result set is broad and often noisy — multiple articles describe the same event, and loosely related pieces still slip through.
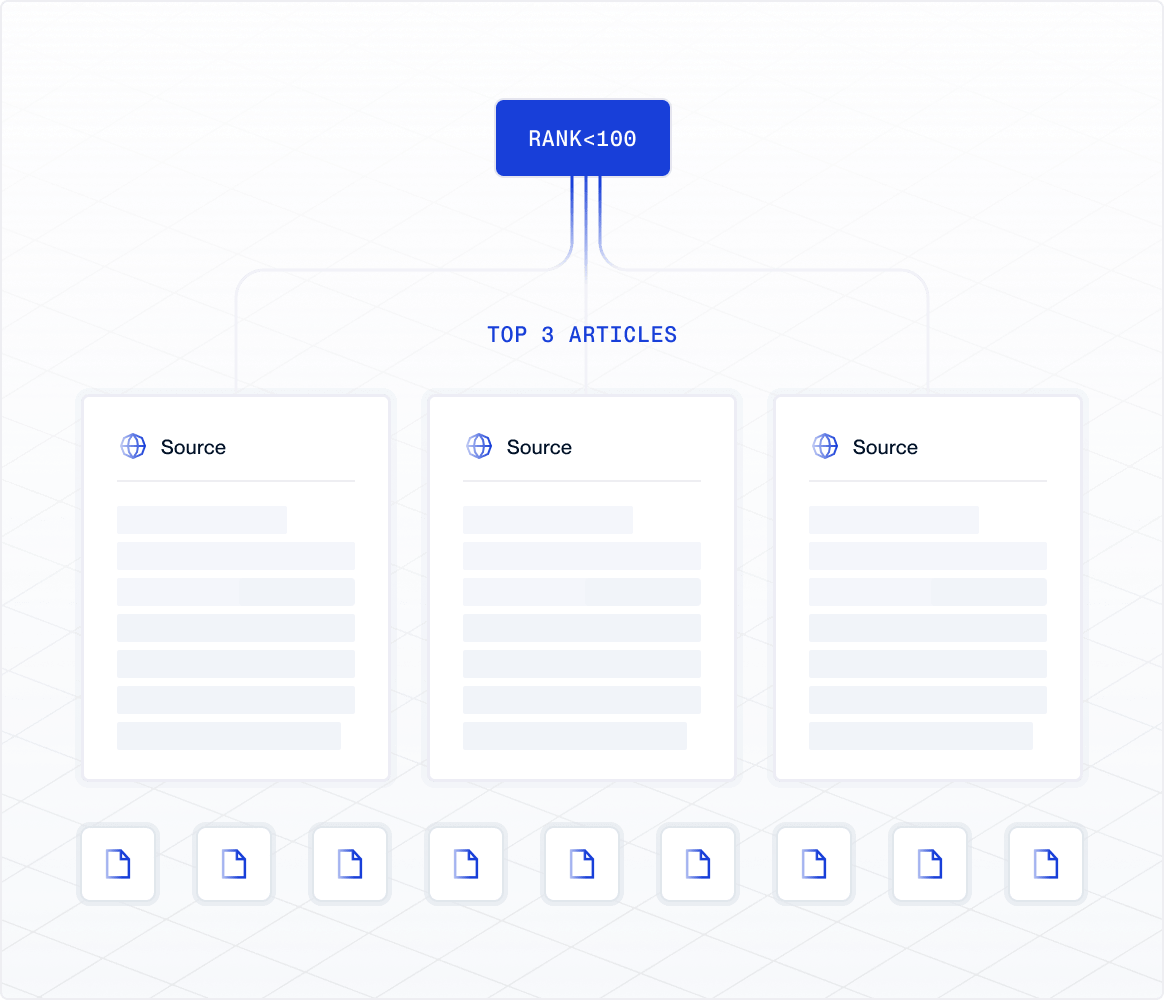
You refine the set by applying a ranking filter: rank < 100. This keeps only high-authority articles, but it doesn’t eliminate duplication. Several top-ranked stories may still cover the same development with minor wording changes.
Finally, using is_headline = true, you extract only articles where your match appears in the headline. This reduces noise, but at a cost: you lose valuable context from articles that discuss the topic meaningfully without naming it in the headline.