





















We were brainstorming what to build with our LangChain + CatchAll integration when the Winter Olympics came up. We were already following the Games and bantering about sports during meetings and chats, but something felt off.
The results were easy to find. Everything else wasn't. Incidents, updates, and context were scattered across the web. You could see what happened briefly or was reported, but not why it mattered or how events connected.
That was our eureka. We decided to build a dashboard that brings everything together into something we can actually query, explore, and understand, making it much easier to follow and analyse the Games beyond just the scoreboard.
The Backend Pipeline: How the System Works
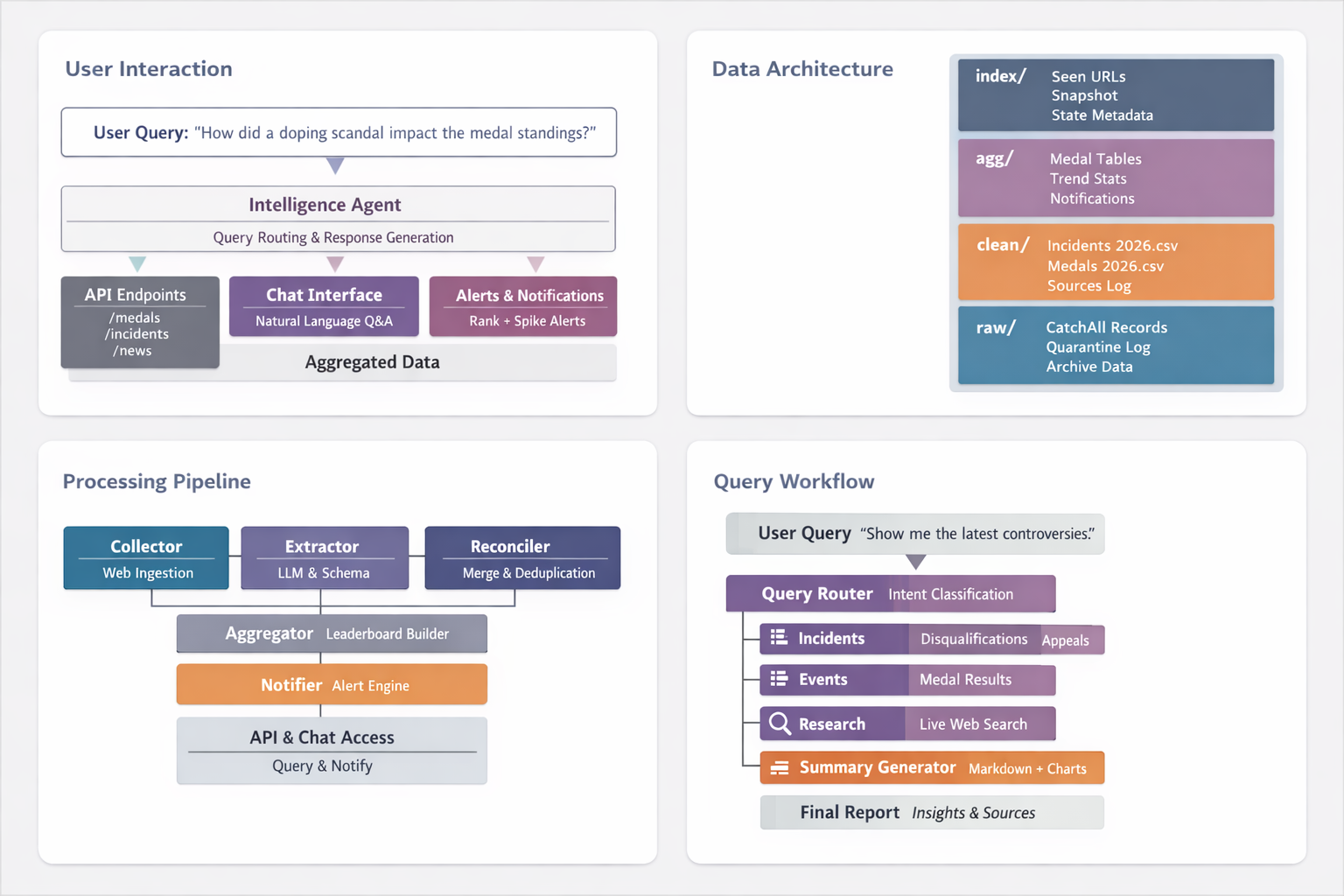
The backend converts scattered web coverage into structured incident intelligence and medal tracking. Instead of browsing articles, we can answer operational questions in seconds: what incidents are happening right now, which ones are high impact, who is affected, and what are the effect medal standings.
The pipeline has five stages.
- Collect: ingests Olympics coverage via Langchain-CatchAll on-demand or on a schedule.
- Extract: uses schema-based LLM extraction to pull structured incidents and medal facts from raw text.
- Reconcile: merges duplicate reports into canonical records, keeping only the highest-confidence version with all supporting sources attached.
- Aggregate: compiles cleaned data into optimised tables for leaderboards and trend charts.
- Serve and alert: exposes API endpoints and generates notifications for rank changes, first gold medals, and high-impact incident spikes.
Each stage maps to a single service file, so it can be run, tested, and scaled independently.
Step 1: Set Up Environment Variables
You need access to two services: CatchAll for data discovery and OpenRouter for structured extraction. Create a .env file in your project root with your API keys and the following config:
CATCHALL_API_KEY="your_key_here"
OPENROUTER_API_KEY="your_key_here"
OPENROUTER_MODEL=openai/gpt-4o-mini
OPENROUTER_ROUTER_MODEL=openai/gpt-4o-mini
OPENROUTER_BASE_URL=https://openrouter.ai/api/v1
OPENROUTER_TIMEOUT_SECONDS=90
OPENROUTER_MAX_RETRIES=2
OPENROUTER_REQUIRE_PARAMETERS=true
SITE_URL=http://localhost:3000
SITE_NAME=Olympics2026Dashboard
POLL_INTERVAL_SECONDS=30
MAX_WAIT_SECONDS=2400
EXTRACTION_MAX_EXCERPT_CHARS=5000
EXTRACTION_MIN_CONFIDENCE=0.45
ENABLE_INTERNAL_SCHEDULER=true
SCHEDULER_FULL_CYCLE_TIME_1=00:00
SCHEDULER_FULL_CYCLE_TIME_2=18:00
API_HOST=0.0.0.0
API_PORT=8000
FRONTEND_ORIGIN=http://localhost:3000
DATA_DIR=dataCatchAll limits calls per second and total quota depending on your plan, so bake in a configurable pause between page calls. EXTRACTION_MIN_CONFIDENCE controls how strict the LLM extraction is. 0.45 is a reasonable starting point that balances recall against noise.
Step 2: Storage and Data Layout
The pipeline is storage-first. Every stage writes to disk in a predictable structure across four layers: raw/ for append-only collection logs, clean/ for canonical deduplicated records, agg/ for precomputed dashboard tables, and index/ for incremental processing state.
At startup, ensure_storage() creates all required folders and CSV files with the correct headers. This matters because your API routes read these files as their source of truth; treating headers as part of the contract keeps the whole pipeline predictable and easy to debug.
Step 3: Collect with CatchAll
Instead of building custom scrapers for each site, we use langchain-catchall to query the web and receive structured records directly. This lets us scale coverage across thousands of sources without individual site integrations.
The query design matters here. We run two sets of targeted searches — one for medal results, one for incidents, written specifically to pull different types of coverage:
Medal queries target official results tables, podium finishes by sport, and daily results by date. Incident queries target disqualifications, appeals, doping violations, eligibility rulings, injuries, and records broken.
MEDAL_QUERIES = [
"Milano Cortina 2026 Winter Olympics official medal table gold silver bronze by country",
"Milano Cortina 2026 Winter Olympics medal winners by event and discipline",
...
]
INCIDENT_QUERIES = [
"Milano Cortina 2026 Winter Olympics disqualification disqualified athlete coach team",
"Milano Cortina 2026 Winter Olympics doping ban suspension anti-doping violation",
...
]Every record is normalized into a consistent structure, title, URL, excerpt, and raw before storage. URLs are normalized so the same article with different formatting doesn't slip through as a new record later.
Before extraction: deduplicate by URL
Before passing anything to the LLM, filter out URLs you've already processed. Extraction costs money; there's no reason to pay twice for the same article.
We maintain data/index/seen_urls.csv as a persistent index. New URLs get logged with a timestamp and move forward to extraction. Repeated URLs increment a hit counter and get skipped. This runs before every extraction cycle, so the API quota only goes toward genuinely new coverage.
Step 4: Extract and Structure with Schema-Based Extraction
Raw records contain useful information, but they're unstructured. A record might mention "athlete disqualified" without telling us the sport, country, or severity. This step fixes that.
Each record goes through two LLM passes. The balanced pass extracts all explicit facts and optimises for recall. If that fails, the strict pass kicks in — it drops anything uncertain and optimises for precision. If both fail, the record goes to quarantine.
Every accepted incident ends up with: incident_type, sport, affected_entity_name, country_code, impact_level, confidence, and source_url. Medal rows require event, sport, winner_name, and a valid IOC country code. Anything below the confidence threshold or missing required fields is rejected.
The JSON schemas in app/schemas/ are doing more work than they appear to. Every extraction call is validated against them before anything touches disk. If the model returns a row that doesn't match the schema, it's rejected at the schema level, not by application logic. This keeps the downstream pipeline clean by design.
Records that fail both passes don't get deleted. They go to data/raw/quarantine_incidents.jsonl and data/raw/quarantine_medals.jsonl for review. This gives you a full audit trail and a way to improve your prompts over time based on what the model struggled with.
Step 5: Reconcile and Deduplicate
Multiple publishers often cover the same incident or medal. Without reconciliation, the same event appears dozens of times with slightly different wording.
Each incident gets a deterministic ID hashed from its core fields: games, incident type, sport, event, affected entity, and date. The same fields always produce the same ID regardless of which publisher reported it. Medal records hash on games, sport, event, medal type, winner name, and country code.
When a new record arrives, the reconciler checks if a canonical version already exists. It only replaces it if the new record has equal or higher confidence. Either way, the source is always logged. The result is one row per canonical incident in clean/incidents_2026.csv, with every reporting outlet linked in a separate sources table. Every incident card on the dashboard can show exactly which outlets reported it and when.
Step 6: Aggregate
Once medals are reconciled, we precompute three tables so the UI never processes raw data on the fly. agg/tally_country.csv is the main leaderboard, ranked by gold then silver then bronze, following the official Olympic tiebreaker. agg/tally_country_sport.csv breaks medals down by country and sport. agg/tally_daily.csv tracks medals per country per day for trend charts.
rebuild_aggregates runs at the end of every full cycle and can also be called independently via run_refresh_all — so you can recalculate leaderboards from existing clean data without hitting the API again.
Step 7: Serve, Alert, and Chat
Notifications fire automatically after every cycle. Three things trigger an alert: a country changing rank, a country winning its first gold, or a country gaining two or more medals since the last refresh. High-impact incidents and sensitive types — disqualifications, doping, appeals — generate their own alerts regardless of medal movement. Every notification gets a deterministic ID so duplicates never accumulate.
The chat interface is the most interesting part. Instead of rigid query filters, chat_router.py routes plain English questions to the right data handler using a two-step LLM pipeline. The first call classifies intent — tally, event lookup, incident lookup, research, or small talk. The second call rewrites the structured response into clean markdown with follow-up questions. If the model router fails, a lightweight fallback reads intent from context and keyword patterns so the chat never goes dark.
All LLM calls go through openrouter_structured.py, which validates every response against a JSON schema before it touches the application. Temperature is set to 0 across all extraction and routing calls — you want deterministic outputs, not creative ones.
Step 8: Putting it all Together
Each service works independently. pipeline.py is the conductor.
run_medals_cycle runs the full medals flow: collect → dedupe → extract → reconcile → aggregate → notify. run_incidents_cycle does the same for incidents. run_refresh_all skips collection entirely and just rebuilds aggregates and notifications from existing clean data. run_full_cycle calls all three in sequence — this is what the scheduler triggers at midnight and 18:00 daily.
Every cycle returns a stats dict: records collected, new, skipped, extracted, quarantined, and merged. The whole pipeline is observable, not a black box.
The full code is available on GitHub. Clone it, add your .env, and run python jobs/run_full_cycle.py to kick off your first cycle. The frontend connects to the same API and is in the same repository.







































