





















tl;dr: We asked Claude to find all AI M&A deals from the past week. It found 3. Our tool found 82 by reviewing 3,561 web pages — in 15–30 minutes, not seconds. Here's why traditional web search fails AI agents, and why we built the world's slowest but most comprehensive web index.
What we’re building
We're building a web index optimized to reflect real-world changes. Think of it as a time series of real-world events, sourced from the web.
Most businesses that need to stay informed about real-world changes are underserved by the current web index. A real estate PE firm, for example, might need to track everything affecting a specific zip code — transport infrastructure projects, new zoning approvals, businesses moving in and out. Anything that can influence property prices.
Traditional web search wasn't built to assemble that picture for them. We want to be the search engine that does.
Web search is built for humans, not research
First, let’s take a look at what a web search is to better understand why it’s worth innovating.
In short, web search solves the problem of finding the best page on the web that might contain an answer to your question.
Web search’s main user was (and still is) you and me – real people looking to find “one perfect web page.”
Usually we have a simple question, like “opening hours of an expo nearby” or “padel racket with even balance”.
For very basic questions, the first link of web search almost always contains the answer (I am not even talking about an AI Overview feature).
To sum up, modern web search is optimized for two things: top K relevance and speed, aka “get the most relevant link ranked high in under a second.”
A modern web search setup is, no doubt, a perfect fit for humans. For simple tasks.
Now let’s think about situations where it’s not a simple question but rather some research task. For example, you need to find all new bus infrastructure projects that are planned in a specific zip code.
Does Google help? Only if someone has already assembled that information on a single page. For most business-specific queries, no one has.
Search like it’s 1996
The a16z team recently published “Search Wars: Episode 2” which references a 1996 Wired article from the pre-Google era, published almost 30 years ago.
I couldn’t get the thought out of my head that web search for AI in 2026 looks very similar to web search for humans in 1996.
Here's the parallel.
In 1996, everyone was trying to classify the knowable universe: understanding the meaning of words, building taxonomies, and organizing the web into the perfect library. The assumption was that if we could just categorize everything, search would be solved.
Then Google came along and said: forget understanding language. Just rank pages by importance.
PageRank didn't solve semantics. It solved the actual human problem — "give me the one best page, fast." Precision won.
That shift from comprehensive cataloging to precision ranking defined web search for the next 30 years.
Now look at where AI search is today. Everyone is focused on the same thing Google perfected: speed and top-k relevance. Give the agent the best link, fast. The entire infrastructure — indexes, retrieval algorithms, APIs — is built around that single mode.
But AI agents don't have the same problem humans had. A human needed the one best page. An AI agent doing deep research needs every relevant page. It doesn't need a librarian pointing to the right shelf. It needs the entire shelf dumped on the table so it can read all of it (because it is very capable of doing so).
In 1996, the industry over-indexed on recall (catalog everything), and Google proved that precision was the real unlock for humans as the end user.
In 2026, the industry is over-indexed on precision (rank the best result), but the end user has changed. For AI agents, recall is the missing unlock.
The retrieval gap
Today, why does someone post anything on the web? Usually, to monetize it.
Search Engine Optimization (SEO) is a technique for improving a website's ranking for a specific keyword. I would say it works quite well.
SEO ensures that high-volume queries get great answers. But for long-tail, specialized queries — the kind businesses actually care about — no one is optimizing for you. The information exists across hundreds of pages. No one has assembled it.
But the information you need is usually on the web.
When a company gets acquired, someone writes about it. When a zoning approval goes through, the local government site publishes it. When a new bus route gets planned, a transportation authority posts an update. The raw information exists. It's just scattered across hundreds or thousands of individual pages, each covering one small piece of the picture.
No one has assembled it for you — because no one else has your exact question. And traditional web search won't assemble it either, because that's not what it's built to do. It's built to find the one best page, not to collect every relevant page and deduplicate the results into a dataset.
This is the gap. Not a gap in what the web knows — a gap in how we retrieve it.
Why deep research fails today: a Claude case study
Deep research is a great way to fix it – let’s give AI access to the web so it can analyze and distill information just as we need it. Sounds good, right?
Yes, but web search tools become the bottleneck. The approach is correct, but the tools aren’t.
Here’s an example:
I asked Claude Opus 4.6, with web search enabled, to find all M&A in the AI industry over the last seven days. It found three major deals.
All three are the right matches. But there are more than 70 other deals; it just didn’t find them. The recall is astonishingly low.
The reason is structural: the web search tool Claude is using is fundamentally unsuited for this task.
Note: For this example, we used a simple Claude instance with web search, not deep research. We did this to make the failure mode easier to follow. Deep research performs better: it found 16 (1,068 sources checked) deals after a few iterations.
Let’s track what web search calls Claude made (each returning 10 links):
Claude: The user wants to find M&A deals in the AI industry from the last 7 days. Let me search for this:
- AI industry mergers acquisitions March 2026
Claude: The search results are giving me general M&A trend articles but not specific deals from the last 7 days (March 12-19, 2026). Let me search more specifically for recent deals:
- AI company acquisition deal March 2026
Claude: Let me search specifically for the last 7 days (March 12-19, 2026) to find more recent deals.
- AI acquisition announced this week March 12-19 2026
Claude: Let me search more specifically for deals in the last 7 days.
- AI startup acquired merger deal week March 13 14 15 16 17 18 19 2026
Claude: Let me do one more targeted search for very recent deals this week.
- "acquired" OR "acquisition" AI company March 2026
Claude:
- Nvidia Coherent investment AI acquisition March 2026
Claude: Now I have enough data to compile a comprehensive answer about AI M&A in the last 7 days (roughly March 12-19, 2026). Let me synthesize the key deals.
Done.
Ok, so in total, Claude got exposed to 60 web pages. Not bad at all. But let’s take a deeper look. I think there are two major problems.
First, it did six very similar searches that yielded very similar results.
Second, there is no listicle or page that aggregates such information.
Therefore, there was only one way for Claude to complete this task – Claude had to “deduce” a dataset of M&A deals that fall under the criteria from multiple web pages.
It failed because the web search tool it uses isn’t good for this task. It is good at finding the best page, but not all pages that match a criterion (great precision, bad recall)
I think this is a very typical example of what deep research is nowadays. It has all the brains to go through massive amounts of information, but it just cannot access it.
It does what a human would do because it’s using a tool designed for humans.
From three to eighty-two results
"Find all pages (or even just information records) that match a criteria”
So, ultimately, a deep research agent doesn’t care about the web itself. It cares about gaining access to real-world information. Web search is the best, most general means to achieve this goal.
In our example, the best-case scenario is for Claude to get a list of records (a dataset), where each record represents a unique M&A event.
And, well, that’s exactly what we built.
Claude, when using CatchAll MCP (that lets AI agents call CatchAll directly from their workflow) for the exact same question:
82 deals found, CatchAll reviewed 3,561 web pages to source the deals.

The caveat? It’s not fast. It actually takes 15-30 minutes to complete such a task, but it produces a clean dataset that your model can just use. And because real-world changes are continuous, CatchAll supports recurring monitors: run the same query weekly, get only new results since the last run. The real estate firm doesn't search once; they subscribe to a zip code.
The evolution of AI search
Phase 1: Search for humans, wrapped for machines. Tools like SerpAPI took web search results designed for people and converted them into machine-readable JSON. A useful starting point, but fundamentally just a translation layer.
Phase 2: Precision-only search APIs (where most of the industry is today). Better filtering, snippets, page summaries, and semantic search. Your agent can describe what it's looking for instead of constructing keyword queries with boolean operators. Easy to integrate, much better developer experience. But under the hood, the index and retrieval algorithms are still optimized for the same thing: speed and top-k relevance. It's still a precision game.
Phase 3: Recall-first search with precision applied downstream (what we're building). This is where we think the industry needs to go. It might sound like a small step, but adding recall as a first-class objective may require rebuilding the indexing and retrieval infrastructure from the ground up.
Benchmarks
There are two general categories of benchmarks for LLMs interacting with the web: simple question-and-answer (e.g., SimpleQA) and reasoning/multi-hop across a sequence of web pages (e.g., SealQA or WebWalker).
But there is no benchmark for complex queries that would require LLMs to gather information from hundreds of web pages.
Note: We do quarterly benchmarks and share results, but the tasks might be skewed to reflect the use cases OUR clients ask for.
Why now
Let's do some simple math. A typical web page, once you strip the HTML and extract the text, is roughly 3,000 tokens. Our M&A query reviewed 3,561 pages. That's about 10.7 million input tokens, plus roughly 1 million output tokens for classification and extraction.
In March 2023, frontier LLM pricing was $30 per million input tokens. That query would have cost around $385. Today, equivalent-quality models cost $0.10–$0.15 per million input tokens. The same query costs $1.50–$2.00. With batch processing, under a dollar.
That's a 200x+ cost reduction in three years.
Context windows moved just as fast. In early 2023, you could fit two or three web pages into a single prompt (8K tokens). Today, 1M-token context windows are standard. That’s enough to hold 300+ pages in a single call and reason across them. a16z calls this trend "LLMflation": inference costs dropping roughly 10x per year for equivalent performance.
Both sides of the equation unlocked at roughly the same time. On the serving side, LLMs can now reliably parse, classify, and deduplicate thousands of web pages per query at a price that makes it a product, not a research experiment. On the receiving side, AI agents can ingest structured datasets of 1,000+ records in a single pass, which means the output of a high-recall search is actually usable.
Our bets on the future of search
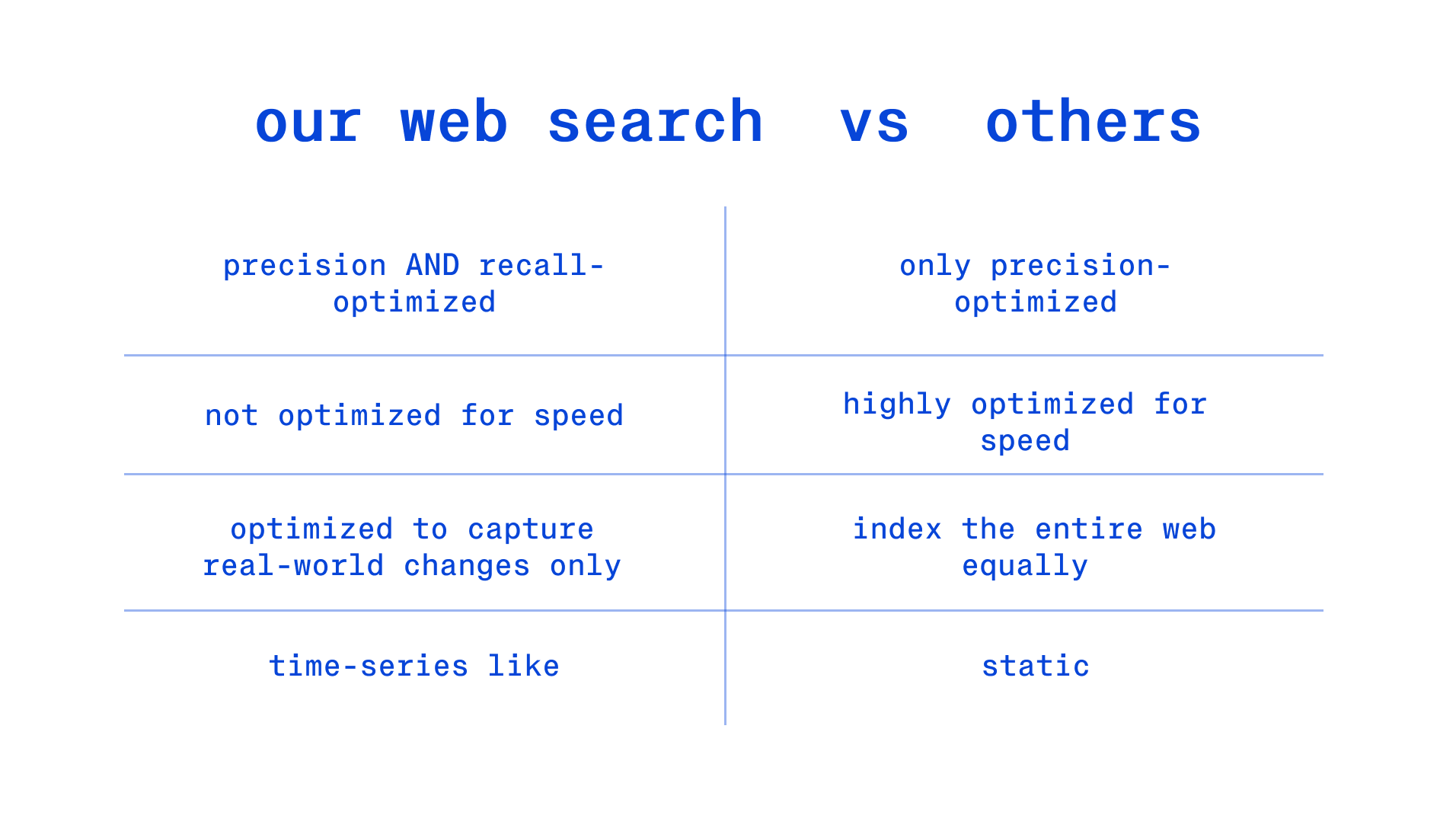
Three bets we're making:
1. Build tools for AI, not adapt human tools for AI.
2. Speed is overrated — 15 minutes for a clean dataset beats 2 minutes for three results.
3. Top-k relevance is one retrieval mode, but not the only one.
We built the world's slowest web search. And we think that's exactly what AI agents need.
If you're building AI agents that need research-grade web access, try our web search tool CatchAll. If you're benchmarking retrieval tools, here's our latest recall benchmark report.
We're early, and we'd love to hear which queries your agents are struggling with.




































