





















Modern websites have made scraping harder with JavaScript-heavy frontends, bot detection systems, rotating CAPTCHAs, and aggressive rate limits. That tension often leads developers to ask whether they should build a custom scraper or use a web scraping API?
Many teams start with a custom scraper that offers full control, but it also means handling infrastructure, debugging broken selectors, managing proxies, and keeping up with website changes.
A managed scraping API can reduce that work. It is especially reliable for teams that care more about getting clean data than maintaining crawling systems.
In this article, we'll compare the two approaches and explain where each makes the most sense.
What is a Custom Web Scraper?
A custom web scraper is a program that engineering teams can build and maintain to extract data directly from web pages. Developers use Python libraries to create custom scrapers, including Scrapy for large-scale crawling, Beautiful Soup for HTML parsing, or browser automation tools like Playwright, Selenium, and Puppeteer for JavaScript-rendered pages.
Custom scraper stacks give engineering teams full control over extraction logic, crawl frequency, request orchestration, and downstream data formatting. For stable targets with predictable HTML structure, engineering teams can often deploy an initial scraper quickly.
However, a scraper that works well on 100 pages may struggle when scaled to millions of requests. The operational complexity that appears as scraping projects scale includes:
- Proxy rotation to avoid IP bans
- CAPTCHA handling through third-party solving services
- Headless browser pools for JavaScript-heavy pages
- Parser maintenance whenever a site changes its HTML structure
- Monitoring and alerting for silent failures
- Rate limit management to avoid getting blocked
What is a Web Scraping API?
A web scraping API is a managed service that handles the crawling, rendering, and parsing infrastructure on your behalf. You send an HTTP request with a target URL or a search query and the API returns structured data, typically as JSON.
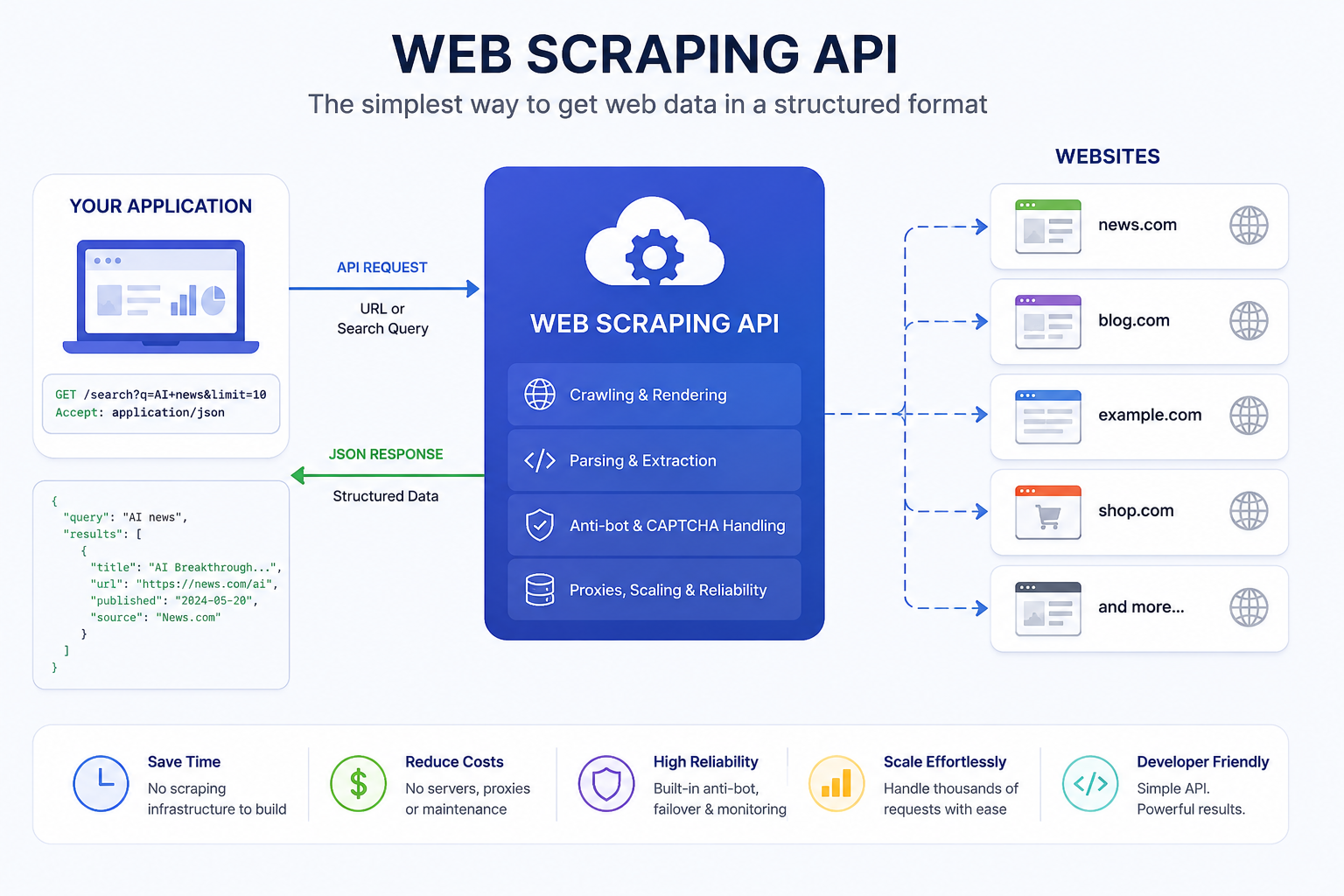
This is the main difference between a custom scraper and a managed scraping API. With a custom setup, your team operates and optimizes the entire data collection infrastructure. This offers maximum control and flexibility but increases long-term engineering effort and maintenance cost. With a managed API, the provider handles infrastructure and scaling, which reduces operational overhead and allows teams to focus on using the data for products, analytics, or AI systems.
Most modern scraping API platforms handle:
- Proxy rotation
- Browser rendering
- Retries and timeouts
- CAPTCHA bypassing
- Anti-bot protection
- Request scaling
- Structured data extraction
This shifts engineering effort away from crawler maintenance and toward downstream analytics, monitoring, and AI workflows.
For teams like data engineering, AI/ML, and analytics running retrieval pipelines, monitoring systems, or AI search workflows, CatchAll Web Search API provides structured, recall-first web retrieval without operating crawler infrastructure internally.
The system indexes 2B+ open web pages and 140,000+ news sources with near real-time refresh cycles, making it suitable for monitoring, intelligence, and AI retrieval workloads that depend on broad coverage and freshness.
What Are the Core Differences Between a Web Scraping API and a Custom Scraper?
Below is a practical comparison of both approaches based on real production use cases.
Custom scraper architectures are often effective for tightly scoped or low-volume extraction workloads. But as data volume grows, operational concerns like anti-bot mitigation and browser orchestration begin consuming significant engineering resources.
This is why many teams eventually migrate to a scraping API. It reduces operational work and allows engineers to focus on product features instead of crawler stability.
What Are the Hidden Costs of Maintaining Custom Web Scrapers?
The real cost of custom scrapers is almost always higher than the initial estimate. The initial build is the cheap part. However, the bulk of the budget actually goes into:
- Parser maintenance: It is the most common ongoing cost. When news or competitor websites redesign layouts, CSS selectors break silently and critical updates may be missed for days.
- IP infrastructure: Residential proxy pools cost adds up fast for high-volume scraping. This is especially true for ecommerce or marketing intelligence use cases where frequent requests across multiple sites require constant rotation, reliability, and low block rates.
- Anti-bot systems: Today, major platforms deploy anti-bot systems like browser fingerprinting, behavioral analysis, and ML-based detection alongside traditional rate limiting. This creates constant maintenance work for large-scale monitoring and AI data collection systems that depend on stable web access.
- JavaScript rendering: Running headless Chromium for every page request is CPU and memory-heavy. Scaling a Playwright or Puppeteer cluster for hundreds of thousands of daily requests requires proper orchestration, auto-scaling, and cost controls.
- Scaling and reliability: As scraping operations grow, even small failures can affect downstream systems. AI data pipelines lose freshness when retrieval breaks, while market intelligence workflows slow down when web data collection becomes delayed or inconsistent.
Managed solutions like CatchAll Web Search API can help teams to handle AI retrieval, monitoring, and large-scale web data workflows. It can remove the need to manage proxies, browser clusters, CAPTCHA handling, and parser maintenance manually.
Unlike traditional search APIs that return only a small set of results, CatchAll is designed for recall-first search and processes over 50,000 web pages per query to improve coverage and relevance.
When to use Custom Scrapers
Custom scrapers are still the right choice in some cases, especially when full control or special logic is required. Use custom scrapers:
- For internal systems, proprietary databases, or legacy tools where no API or managed support exists.
- When a website requires user logins, session handling, or access to private internal systems.
- When workflows need multi-step actions like pagination, form filling, or cross-page linking.
- When data needs are small and websites change rarely.
- When full control is necessary over how and when data is collected.
In many cases, custom scrapers are effective at first. However, the teams should revisit this choice as scale grows, since managed solutions are more cost-efficient over time.
When to use a Managed API
Managed scraping APIs are usually the better choice when you need scale, reliability, structured output, and easy integration into data or AI workflows. Use a managed API when:
- RAG pipelines or AI agents need real-time web data in a structured format without building custom crawlers.
- Tracking large numbers of sources in real time, where continuous coverage and freshness matter more than custom scraping logic.
- Consistent, normalized data is needed across multiple sources to support accurate trend analysis, benchmarking, and reporting.
- Scaling, retries, and stability are handled automatically for high-volume extraction tasks.
- Production-ready web data is needed quickly, without the delay of building and debugging scrapers.
How to Choose the Right Approach for Your Team?
The choice between a custom scraper and a web scraping API depends mainly on your team's capacity, scale, and long-term needs. Consider:
- Team size and engineering capacity: Custom scrapers are easier to maintain with a large engineering team. Otherwise, scraping APIs are better suited to small- to medium-sized teams.
- Control and flexibility requirements: When teams need complete control over crawling, extraction, and browser interactions, custom scrapers work better. Managed APIs are more practical for standardized data collection workflows.
- Authenticated and private systems: Custom scrapers are usually preferred for internal tools or websites that require login handling. Managed APIs work best for public web data collection at scale.
- Scraping scale and infrastructure needs: It is easier to manage custom scrapers for smaller workloads. For large-scale scraping, APIs reduce the burden of proxy management, retries, and anti-bot handling.
- Structured output and AI integration: Managed APIs are more useful when teams need clean JSON data for analytics or AI systems. Custom scrapers are better for highly specialized parsing requirements.
- Deployment speed and maintenance effort: APIs help teams launch faster with less operational overhead. Custom scrapers take longer to stabilize and require ongoing maintenance as websites change.
In most real-world cases, the decision comes down to the total cost of ownership. Custom scrapers may look cheaper initially, but APIs are often more cost-efficient over time due to lower maintenance and infrastructure needs.
There's a free tier to test your use case without a commitment. Get started with the documentation here.
Summary
Both custom scrapers and the most reliable web scraping APIs have valid use cases. Custom scrapers offer full control and flexibility that is useful for niche or highly specialized workflows. On the other hand, Managed APIs can help to reduce complexity. They handle infrastructure, scaling, and anti-bot challenges, which makes them more suitable for production systems that need stability and speed.
For developers exploring this space, the CatchAll Web Search API is a practical option to test. It offers a free tier and is designed for structured web retrieval and large-scale monitoring use cases.
Try it here and start with 2,000 free credits on signup at https://platform.newscatcherapi.com/catchall, enough to run around 20 Lite queries or explore Base mode across multiple topics.
Questions? Reach us at support@newscatcherapi.com.
FAQs
High-volume Web Scraping via API – What's best?
A managed web scraping API is usually best for high-volume scraping. It handles scaling, proxies, and blocking issues automatically. This reduces infrastructure load and improves reliability compared to custom scrapers.
How to use Web Scraping API?
Send an HTTP request to an endpoint with your target URL or query. The API returns structured data, often in JSON format. Most providers also include documentation and SDKs for easy integration.
What is an API in Web Scraping?
An API in web scraping is a managed interface that lets you collect web data without building scrapers yourself. It handles crawling, parsing, and infrastructure tasks in the background.
What is the best Web Scraping API?
The best web scraping API depends on your use case. Some focus on raw extraction, while others support search and monitoring. The right choice depends on scale, freshness needs, and integration requirements.

.png)






































