





















Information retrieval was built for the Google and search engine era.
The goal was simple: rank the best URLs fast.
Crawlers indexed trusted sources and surfaced only the top links. This worked for search because it reduced bounce rate and helped UX.
But AI systems do more than information retrieval. They reason over the data they have access to, synthesize answers, and classify patterns.
So, if the model only sees a fraction of the available information, every decision is based on an incomplete picture.
The noise fallacy
Precision measures quality and correctness. If a result shows up, it should be right.
Recall is about coverage. Of all the relevant information out there, how much did we actually find?
They solve different problems. Precision helps you avoid noise and false alarms. Recall helps you avoid missed opportunities. The usual pushback to prioritising recall is: “ Aren’t we just adding noise and sacrificing quality?”
It’s a reasonable worry, but it assumes that low-visibility sources are mostly junk. In practice, that assumption doesn’t hold.
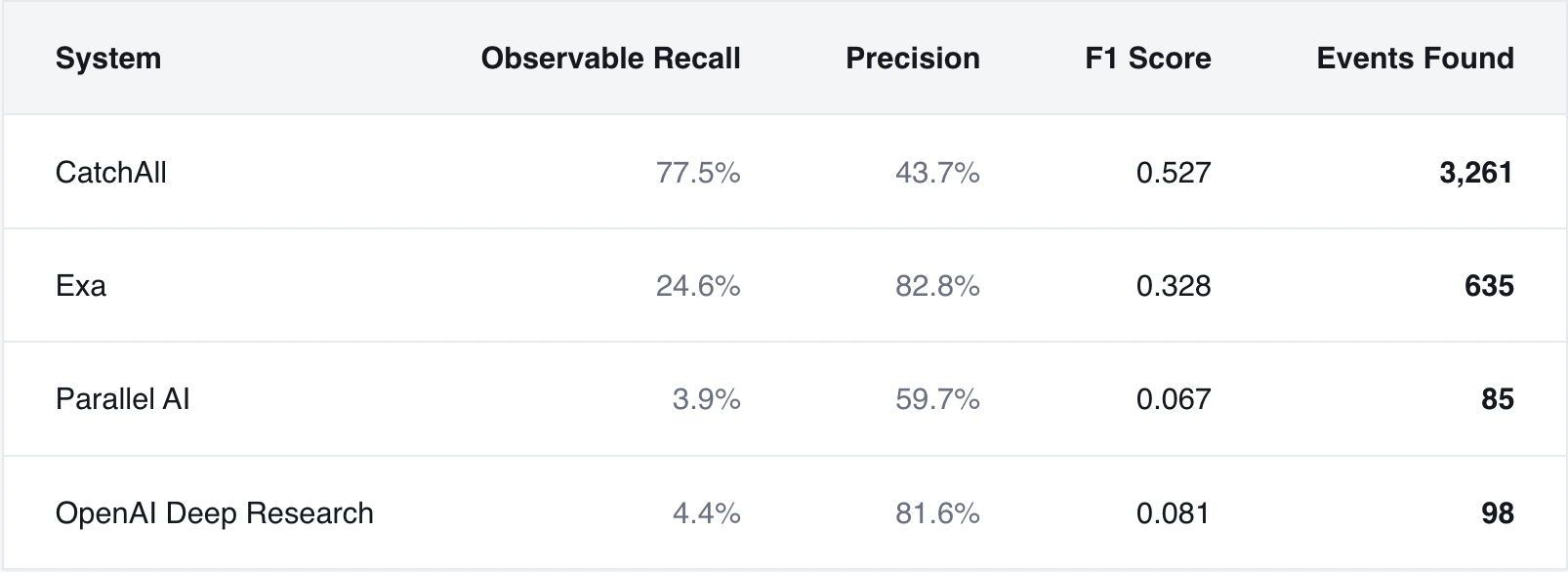
To prove it, we evaluated four systems: CatchAll, Exa Websets, Parallel AI FindAll, and OpenAI Deep Research, across 35 real-world business queries. Same questions. Same time window. Same evaluation criteria.
- CatchAll returned 3,261 records.
- Exa returned 635.
- Parallel returned 85.
- OpenAI returned 98.
Since more results only matter if they’re relevant, we measured relevance directly.
After initial manual tagging the relevance of 1000 examples, we fine-tuned a large LLM model (gemini-2.5-pro), achieving 92% accuracy compared to manual tagging.
The experiment: what happens when you increase recall
We tested each tool across four key categories: AI funding rounds, product recalls, data breaches, and labor strikes. We fine-tuned all for the return of maximum results (finding all relevant events, not ranking the best).
We measured three metrics:
- Observable recall: how many events each system captured
- Precision: how many returned results were relevant
- F1: overall balance between coverage and precision
Important: we didn’t measure absolute recall (every event that actually happened). We measured recall within the observable universe, the set of events found by at least one provider. That keeps comparisons fair, since every system is judged against the same pool.
Here's what we found:
CatchAll captured roughly 3 out of 4 relevant events. While other search APIs captured about 1 out of 4 or fewer across each category:
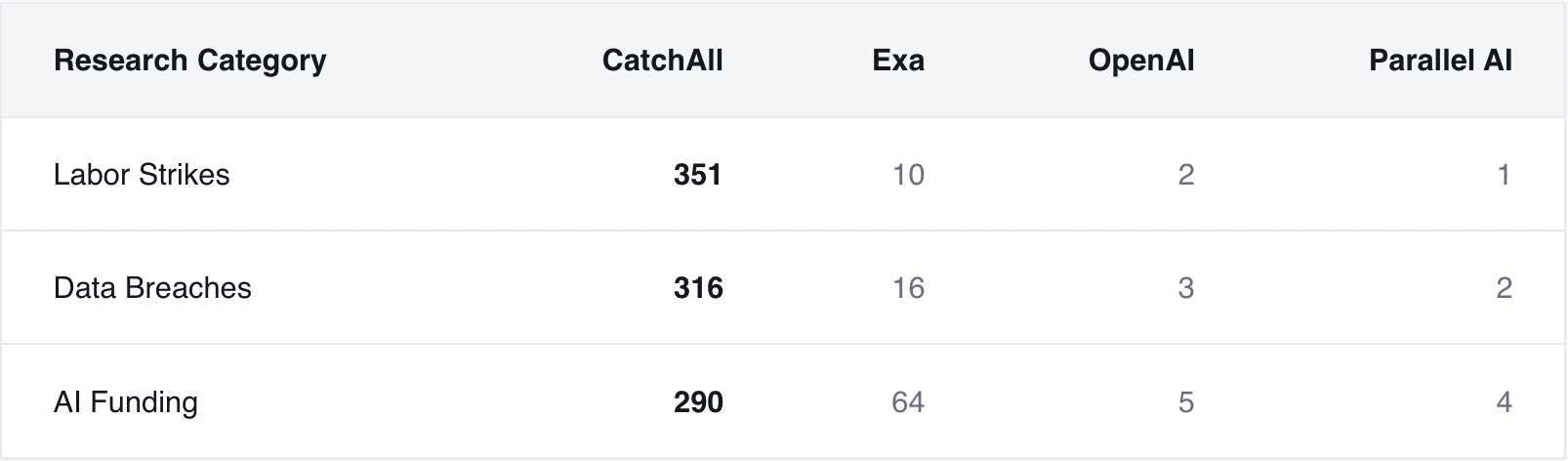
These aren’t small misses. Entire clusters of events never appear in the other results.
Deduplication: making recall usable
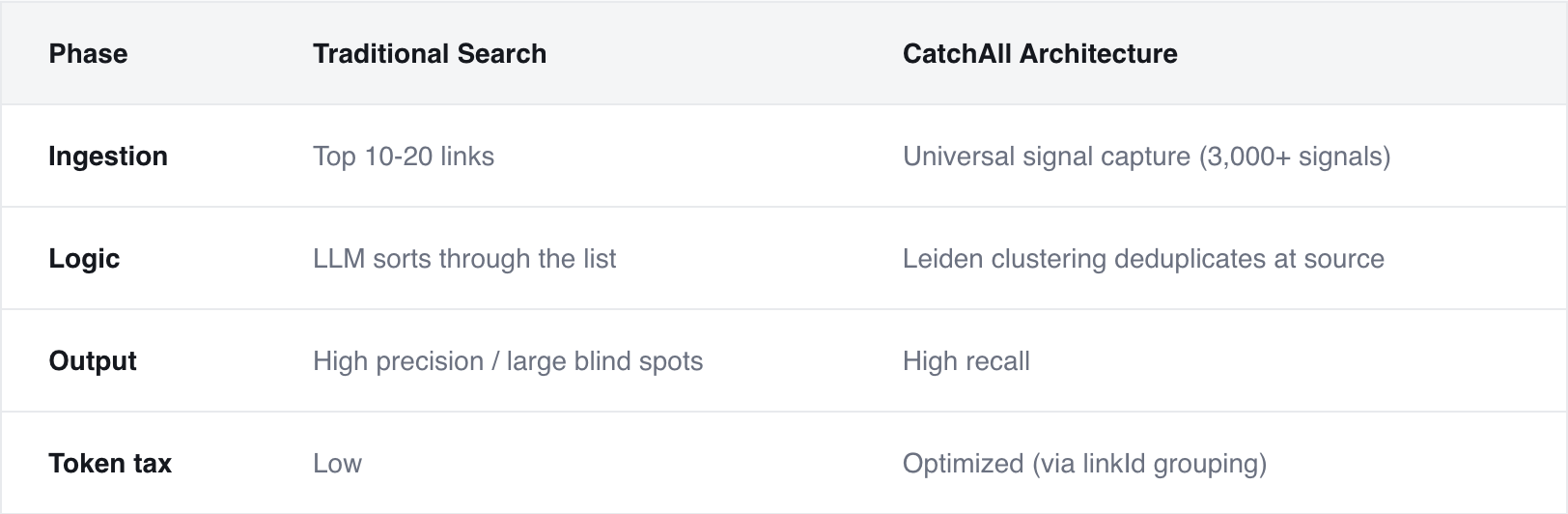
Another pushback to high recall is duplication. If you feed an AI agent 500 raw links about the same acquisition, you are paying a token tax. That’s the cost of having an LLM read the same 50 paragraphs 500 times just to tell you it’s one event.
To solve this, we use two processes:
- The Leiden protocol: We use Leiden Clustering—a community detection method—to treat the web as a network of information. It identifies connected articles across the web talking about the same thing and groups them into a single cluster under a unique linkId.
- Iterative LLM-based clustering: Once grouped, we use LLMs to iteratively refine these clusters. The model compares the nuances of the text to ensure that even if headlines are different, the underlying event is deduplicated.
This combined approach allows CatchAll to maintain 94.5% uniqueness. This is significantly higher than Exa (71.5%) or Parallel AI (67.6%), and puts us on par with OpenAI Deep Research (97.4%)but with superior coverage.
This shows that broad coverage and clean results are not mutually exclusive.
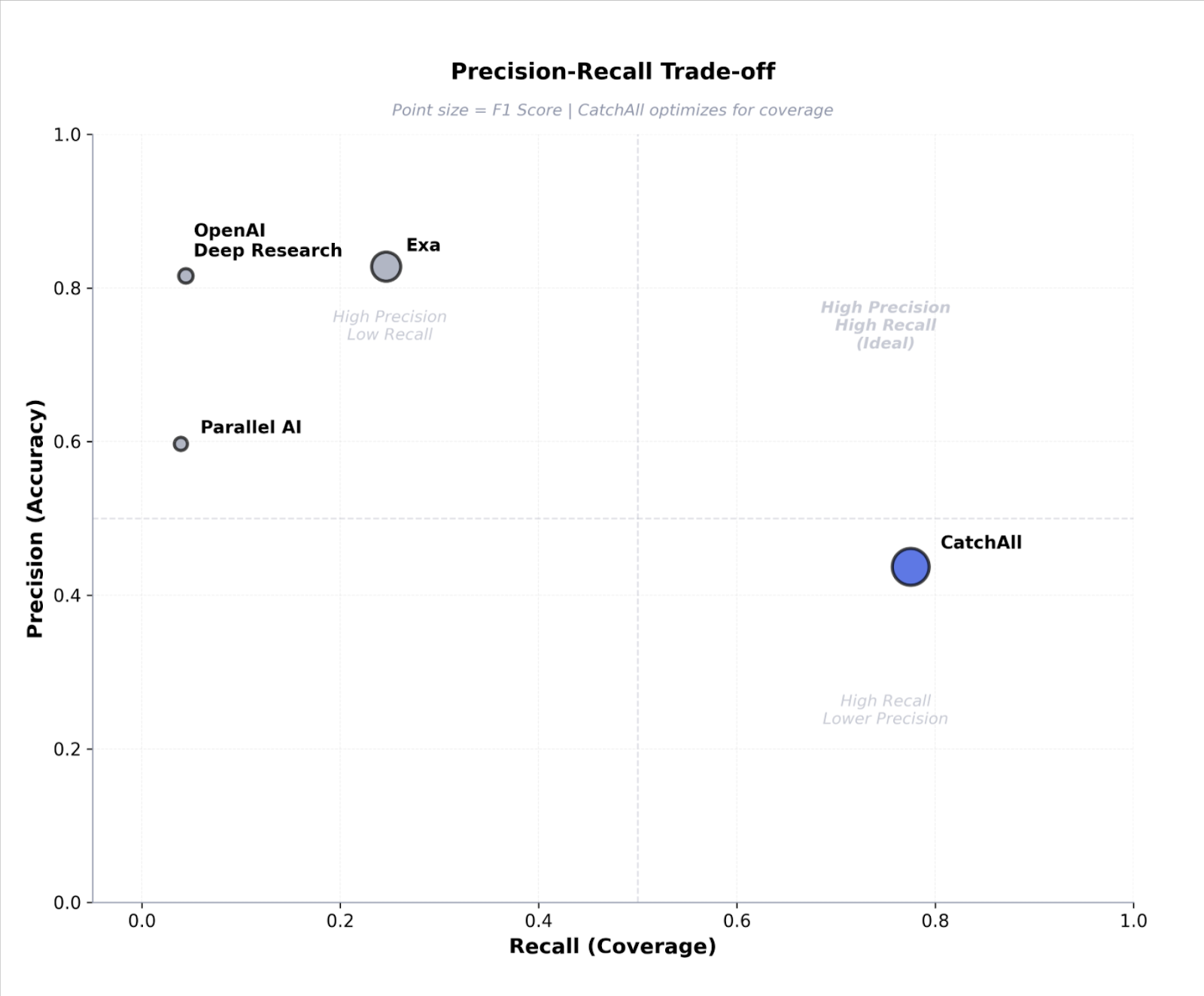
When precision-first wins
Recall-first isn't a universal prescription. CatchAll's 77.5% recall comes at 43.7% precision cost. Competitors achieve 60-80% precision with 2-25% recall. Neither is wrong. They solve different problems.
Precision-first wins when:
- Your query naturally returns 20-30 results (especially geographically specific)
- False positives trigger expensive actions like automated trading
- You need coherent storytelling over comprehensive data (narrative synthesis)
- Top-10 results are sufficient
However, if you're building systems that can't afford blind spots (such as compliance monitoring, risk intelligence, or knowledge bases for RAG), then optimize for recall.
You can clean data. You can't materialize missing data.
Why AI can fix precision, but not recall
You can use AI to make up for the 43% precision cost, but you can’t use it to invent missing data.
False positives are a computational problem. If your crawler brings in noise, LLMs can score relevance, remove duplicates, and rank results by confidence in seconds. The cost of noise filtering is cheap, fast, and scalable.
False negatives are different. If an event never enters your system, no model can recover it.
- You can’t fine-tune on examples you never saw.
- You can’t retrieve context that doesn’t exist in your database.
That’s permanent data loss that leads to partial intelligence. We start with a broader slice of reality and then filter down.
This is why CatchAll wins the balance between coverage and quality(F1). As shown in our most recent benchmarks.
We outperform the competition with an F1 score of 0.527, scoring 60% higher than the closest competitor, Exa.





































