





















Architecture Overview
The system uses a three-stage agent pipeline where each agent processes and enriches the data:

Why this architecture?
- Separation of concerns — each agent has a focused role
- Context passing — later stages build on earlier analysis
- Consistent output — structured reports regardless of input volume
- Domain expertise — agent backstories encode industry knowledge
Prerequisites
- Python 3.10+
- NewsCatcher CatchAll API key
- Google Gemini API key
Project Setup
1. Create project structure
mkdir risk_management_agent && cd risk_management_agent2. Define dependencies
Create pyproject.toml:
[project]
name = "risk_management_agent"
version = "1.0.0"
requires-python = ">=3.10"
dependencies = [
"crewai[tools]>=0.86.0",
"newscatcher-catchall-sdk>=0.2.0",
"python-dotenv>=1.0.0",
]
[project.scripts]
run_crew = "risk_management_agent.main:run"
[tool.crewai]
type = "crew"
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[tool.hatch.build.targets.wheel]
packages = ["src/risk_management_agent"]3. Install
crewai install4. Configure environment
Create .env in the project root:
NEWSCATCHER_API_KEY=your_catchall_key
GEMINI_API_KEY=your_gemini_keyData Ingestion
CatchAll provides three ways to get data:
- Monitor — Continuous monitoring with periodic pulls
- Job — One-time search with structured extraction
- New Job — Create and wait for completion
Create src/risk_management_agent/main.py:
import os
import time
from datetime import datetime
def get_client():
from newscatcher_catchall import CatchAllApi
return CatchAllApi(api_key=os.getenv("NEWSCATCHER_API_KEY"))
def fetch_from_monitor(monitor_id: str) -> dict:
"""Pull latest results from a running monitor."""
client = get_client()
results = client.monitors.pull_monitor_results(monitor_id)
return to_dict(results)
def fetch_from_job(job_id: str) -> dict:
"""Get results from a completed job."""
client = get_client()
results = client.jobs.get_job_results(job_id)
return to_dict(results)
def create_job(query: str, context: str, schema: str) -> dict:
"""Create a new job and wait for completion."""
client = get_client()
job = client.jobs.create_job(
query=query,
context=context,
schema=schema
)
# Poll until complete
while True:
status = client.jobs.get_job_status(job.job_id)
if any(s.status == "completed" and s.completed for s in status.steps):
break
current = next((s for s in status.steps if not s.completed), None)
if current:
print(f"Step {current.order}/7: {current.status}")
time.sleep(30)
return to_dict(client.jobs.get_job_results(job.job_id))
def to_dict(obj):
"""Recursively convert API objects to dicts."""
if obj is None or isinstance(obj, (str, int, float, bool)):
return obj
if isinstance(obj, datetime):
return obj.isoformat()
if isinstance(obj, dict):
return {k: to_dict(v) for k, v in obj.items()}
if isinstance(obj, (list, tuple)):
return [to_dict(i) for i in obj]
if hasattr(obj, 'model_dump'):
return to_dict(obj.model_dump())
if hasattr(obj, '__dict__'):
return {k: to_dict(v) for k, v in obj.__dict__.items()
if not k.startswith('_')}
return str(obj)
Usage examples
# From a monitor (for continuous use cases)
data = fetch_from_monitor("50e6a6bc-bb49-4968-8f3c-1f984359cf62")
# From a previous job
data = fetch_from_job("ab2b9609-aa5f-41c4-a894-87fcfa1cbe04")
# Create new job with custom query
data = create_job(
query="Supply chain disruptions at German car manufacturers",
context="Focus on semiconductor shortages, logistics delays, labor strikes",
schema="Supplier [NAME] Event [TYPE] Impact [DESCRIPTION] Severity [High/Medium/Low]"
)Building the Processing Tool
The tool formats raw API results for agent consumption. Agents work better with structured text than raw JSON.
Create src/risk_management_agent/tools/risk_tool.py:
import json
import re
from typing import Type, Dict, Any
from crewai.tools import BaseTool
from pydantic import BaseModel, Field
class RiskDataInput(BaseModel):
results_json: str = Field(..., description = "JSON string of API results")
class RiskDataTool(BaseTool):
"""Formats CatchAll results for risk analysis."""
name: str = "process_risk_data"
description: str = "Processes news data to extract supply chain risks"
args_schema: Type[BaseModel] = RiskDataInput
def _run(self, results_json: str) -> str:
try:
data = json.loads(results_json)
return self._format(data)
except json.JSONDecodeError as e:
return self._extract_partial(results_json, str(e))
def _format(self, data: Dict[str, Any]) -> str:
lines = [
"## Risk Intelligence Data",
f"**Records:** {data.get('valid_records', 0)}",
""
]
for i, record in enumerate(data.get('all_records', []), 1):
lines.append(f"### {i}. {record.get('record_title', 'Untitled')}")
enrichment = record.get('enrichment', {})
if enrichment:
if enrichment.get('schema_based_summary'):
lines.append(f"**Summary:** {enrichment['schema_based_summary']}")
if enrichment.get('affected_manufacturers'):
lines.append(f"**Manufacturers:** {enrichment['affected_manufacturers']}")
if enrichment.get('disruption_causes'):
lines.append(f"**Causes:** {enrichment['disruption_causes']}")
impact = enrichment.get('impact_details')
if impact and isinstance(impact, dict):
lines.append("**Impact:**")
for k, v in impact.items():
if v:
lines.append(f" - {k}: {v}")
citations = record.get('citations', [])[:3]
if citations:
lines.append("**Sources:**")
for c in citations:
lines.append(f" - [{c.get('title', '')}]({c.get('link', '')})")
lines.append("")
return "\\n".join(lines)
def _extract_partial(self, raw: str, error: str) -> str:
"""Fallback extraction when JSON is malformed."""
lines = [f"## Partial Extraction (JSON error: {error})", ""]
titles = re.findall(r'"record_title":\\s*"([^"]+)"', raw)
if titles:
lines.append("### Events Found:")
for title in titles:
lines.append(f"- {title}")
return "\\n".join(lines)
Why format as text?
LLMs process structured text more reliably than nested JSON. The tool converts API responses into a format that agents can reason about directly.
Defining Agents
Agents are defined in two parts: YAML configuration for declarative settings and Python code for runtime behavior.
YAML Configuration
Create src/risk_management_agent/config/agents.yaml:
news_intelligence_officer:
role: Supply Chain Intelligence Officer
goal: >
Extract risk signals from news data affecting {target_manufacturers}.
Identify early warning signs before they impact production.
backstory: >
Former intelligence analyst specializing in supply chain security.
Expert at identifying semiconductor, logistics, and geopolitical risks.
risk_analyst:
role: Risk Assessment Analyst
goal: >
Categorize and score supply chain risks for {target_manufacturers}.
Assess severity and identify patterns across events.
backstory: >
Risk analyst with operations research background.
Expert in automotive supply chain vulnerabilities and JIT production.
executive_report_analyst:
role: Executive Risk Communicator
goal: >
Create clear risk summaries showing global events and business impact
for {target_manufacturers}.
backstory: >
Former Chief of Staff at automotive companies.
Translates complex risk data into actionable executive briefings.Python Agent Definitions
In crew.py, the @agent decorator links YAML config to runtime settings:
from crewai import Agent, LLM
from crewai.project import CrewBase, agent
@CrewBase
class RiskManagementCrew:
agents_config = 'config/agents.yaml'
def __init__(self):
self._llm = LLM(
model="gemini/gemini-2.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=0.2
)
@agent
def news_intelligence_officer(self) -> Agent:
"""Stage 1: Extract risk signals from raw news data."""
return Agent(
config=self.agents_config['news_intelligence_officer'],
tools=[RiskDataTool()], # Custom tool for processing
llm=self._llm,
verbose=True,
max_iter=5 # Limit reasoning iterations
)
@agent
def risk_analyst(self) -> Agent:
"""Stage 2: Categorize and score risks."""
return Agent(
config=self.agents_config['risk_analyst'],
llm=self._llm,
verbose=True,
allow_delegation=False # Don’t pass work to other agents
)
@agent
def executive_report_analyst(self) -> Agent:
"""Stage 3: Generate executive summary."""
return Agent(
config=self.agents_config['executive_report_analyst'],
llm=self._llm,
verbose=True,
allow_delegation=False
)Agent Design Principles
- Keep backstories short but specific to the domain
- Goals should be actionable, not abstract
- Reference input variables like
{target_manufacturers}for context - Use
allow_delegation=Falseto prevent agents from passing work around - Assign tools only to agents that need them
Creating Tasks
Tasks define what each agent does and how they pass context between stages.
YAML Configuration
Create src/risk_management_agent/config/tasks.yaml:
gather_risk_intelligence:
description: >
Analyze {valid_records} news records for supply chain risks.
For each risk signal:
- What’s happening globally
- Which manufacturers/suppliers affected
- Financial and operational impact
- Source citations
Focus: {focus_areas}
Data: {news_data}
expected_output: >
Intelligence brief with risk count, global context,
and detailed findings for each identified risk.
agent: news_intelligence_officer
analyze_and_categorize_risks:
description: >
Categorize risks from Stage 1 into:
- SEMICONDUCTOR_SHORTAGE
- RAW_MATERIAL_SCARCITY
- LOGISTICS_DELAY
- LABOR_DISRUPTION
- GEOPOLITICAL
- SUPPLIER_FINANCIAL
- ENERGY_CRISIS
- COMPETITION
For each: category, severity (CRITICAL/HIGH/MEDIUM/LOW),
what’s happening, business impact.
expected_output: >
Categorized risk report with counts by category
and severity-ranked findings.
agent: risk_analyst
context:
- gather_risk_intelligence
generate_executive_report:
description: >
Create executive risk summary for {target_manufacturers}.
Structure:
- Risk dashboard (category counts, severities)
- Critical/High risks (detailed)
- Medium risks (summary table)
- Low/Monitoring items (brief list)
- Key metrics (financial exposure, production impact)
expected_output: >
Markdown report with dashboard, categorized risks,
and business metrics.
agent: executive_report_analyst
context:
- gather_risk_intelligence
- analyze_and_categorize_risksPython Task Definitions
In crew.py, the @task decorator connects YAML config to execution:
from datetime import datetime
from crewai import Task
from crewai.project import task
@CrewBase
class RiskManagementCrew:
tasks_config = 'config/tasks.yaml'
@task
def gather_risk_intelligence(self) -> Task:
"""Stage 1: Extract raw intelligence from news data."""
return Task(
config=self.tasks_config['gather_risk_intelligence']
)
@task
def analyze_and_categorize_risks(self) -> Task:
"""Stage 2: Categorize by type and severity."""
return Task(
config=self.tasks_config['analyze_and_categorize_risks']
)
@task
def generate_executive_report(self) -> Task:
"""Stage 3: Format as executive report."""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
return Task(
config=self.tasks_config['generate_executive_report'],
output_file=f'reports/risk_report_{timestamp}.md'
)Context Passing
The context field in YAML links tasks together:
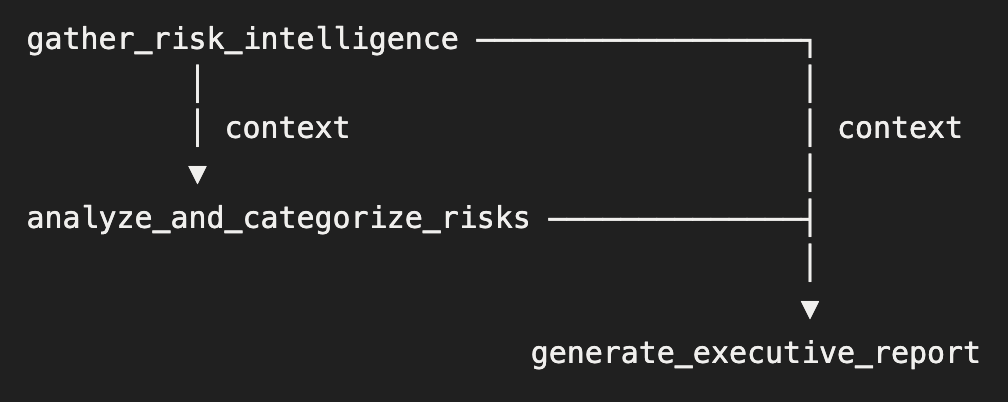
analyze_and_categorize_risksreceives output fromgather_risk_intelligencegenerate_executive_reportreceives output from both previous tasks- Each stage builds on the analysis of previous stages
Assembling the Crew
The crew wires agents and tasks together. The @crew decorator creates the execution pipeline.
from crewai import Crew, Process
from crewai.project import crew
@CrewBase
class RiskManagementCrew:
agents_config = 'config/agents.yaml'
tasks_config = 'config/tasks.yaml'
# ... agents and tasks defined above ...
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents, # Auto-collected from @agent methods
tasks=self.tasks, # Auto-collected from @task methods
process=Process.sequential,
verbose=True,
memory=False, # Disable cross-run memory
planning=False # Disable pre-execution planning
)Crew Configuration Options
| Setting | Value | Purpose |
|----------| ------------------ | ---------------------------------|
| process | Process.sequential | Tasks run in order |
| verbose | True | Show agent reasoning |
| memory | False | No persistence between runs |
| planning | False | Skip pre-execution planning steps|Key Patterns
self.agentsandself.tasksare auto-populated by the decoratorsProcess.sequentialensures Stage 2 waits for Stage 1, etc.output_fileon the final task saves the report automatically
Running the Pipeline
Complete the main.py entry point:
import json
from datetime import datetime
from risk_management_agent.crew import RiskManagementCrew
def run(mode: str = None, source_id: str = None):
"""Run the risk management pipeline."""
# Get data (using one of the ingestion methods)
if mode == "monitor":
data = fetch_from_monitor(source_id)
elif mode == "job":
data = fetch_from_job(source_id)
else:
data = create_job(
query="Supply chain disruptions at German car manufacturers",
context="Focus on semiconductor, logistics, labor, geopolitical risks",
schema="Supplier [NAME] Event [TYPE] Impact [DESCRIPTION] Severity [Level]"
)
# Prepare inputs for the crew
inputs = {
'target_manufacturers': 'BMW, Mercedes-Benz, Volkswagen, Audi',
'current_date': datetime.now().strftime('%Y-%m-%d'),
'news_data': json.dumps(data, indent=2),
'valid_records': str(data.get('valid_records', 0)),
'date_range_start': data.get('date_range', {}).get('start_date', ''),
'date_range_end': data.get('date_range', {}).get('end_date', ''),
'focus_areas': 'semiconductor, logistics, labor, geopolitical, supplier financial'
}
# Run the crew
result = RiskManagementCrew().crew().kickoff(inputs=inputs)
print(f"\\nReport saved to reports/")
return result
if __name__ == "__main__":
import sys
mode = sys.argv[1] if len(sys.argv) > 1 else None
source_id = sys.argv[2] if len(sys.argv) > 2 else None
run(mode, source_id)Execute
# Interactive mode
crewai runSample Output
# GERMAN AUTOMOTIVE SUPPLY CHAIN RISK REPORT
**Date:** 2025-12-16
**Period:** 2025-11-29 to 2025-12-04
**Records Analyzed:** 3
## Risk Dashboard
| Category | Count | Highest Severity |
|----------|-------|------------------|
| SEMICONDUCTOR_SHORTAGE | 2 | HIGH |
| GEOPOLITICAL | 1 | CRITICAL |
| LABOR_DISRUPTION | 1 | HIGH |
## Critical Risks
### German Auto Industry Crisis
**Category:** GEOPOLITICAL
**Severity:** 🔴 CRITICAL
**What’s Happening:** Multiple German automakers facing production threats
due to combined pressures from Chinese competition, US tariffs, and weak
domestic demand.
**Impact:** €13B refinancing obligations, 50,000 job cuts planned
**Affected:** BMW, Volkswagen, Mercedes-Benz
**Sources:** [Reuters](https://...), [Handelsblatt](https://...)
## High Risks
...
## Key Metrics
- Financial Exposure: €15.5 B
- Jobs at Risk: 52,000
- Production Capacity Affected: 12%Summary
This integration combines:
- CatchAll for structured news extraction with enrichment
- CrewAI's Crews for multi-agent sequential processing
- Domain-specific agents encoding industry expertise
The result is a risk monitoring system that transforms raw news into executive-ready reports with categorization, severity scoring, and business impact analysis.





































