





















How To Annotate Entities With Spacy PhraseMatcher
By the end of this article, you will be able to write a name matching pipeline using spaCy’s PhraseMatcher. It will find and label organization names and their stock ticker symbols.
DEMO
You can find the accompanying web app here.
In this tutorial, we'll:
- Learn about the spaCy PhraseMatcher class
- Use PhraseMatcher to create a text annotation pipeline that labels organization names and stock tickers
- Learn a quick-and-easy way to scrape Wikipedia tables directly into pandas DataFrame
- Use spaCy's displacy class to visualize custom entities
The Problem We're Trying To Solve In This Article
While working on the named-entity recognition (NER) pipeline for one of our previous articles, we ran into some issues with the default spaCy NER model. The pipeline aimed to detect significant events like acquisitions. For this, we used spaCy’s in-built NER model to detect organization names in news headlines. The problem is that the model is far from perfect so it doesn’t necessarily detect all organizations. And this is to be expected for entities like organization names that have variations and new additions.
There are two ways to solve this issue. We can either train a better statistical NER model on an updated custom dataset or use a rule-based approach to make the detections. The funny thing about this choice is that it’s not really a choice. You see, to train a better NER model we would need to label text data. And the best way to optimize the data annotation process is to automate it (or parts of it) using a rule-based method.
So, that’s exactly what we are doing to do in this article. We’ll learn about spaCy’s PhraseMatcher and use it to annotate organization names and stock ticker symbols.
Introduction To spaCy PhraseMathcer
The PhraseMatcher class enables us to efficiently match large lists of phrases. It accepts match patterns in the form of Doc objects that can contain many tokens.
First, let's install spaCy.
The next step is to initialize the PhraseMatcher with a vocabulary. Like Matcher, the PhraseMatcher object must share the same vocabulary with the documents it will operate on.
After initializing the PhraseMathcer object with a vocab, we can add the patterns using the .add() method.
NOTE: Each phrase string has to be processed with the nlp object to create Doc objects for the pattern dictionary. Doing this in a simple loop or a list comprehension can easily become inefficient and slow. If we only need to match for text patterns (and not other attributes) we can use nlp.make_doc instead, which only runs the tokenizer. We can also use nlp.tokenizer.pipe for an extra speed boost as it processes the texts as a stream.
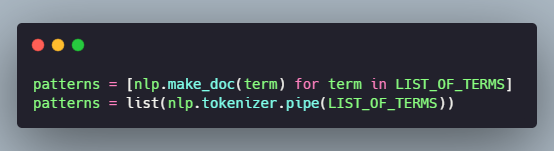
Now that we have added the desired phrases, we can use the matcher object to find them in some news text.
Matching On Other Token Attributes
By default, the PhraseMatcher matches on the verbatim token text, i.e., .text attribute. Using the attr argument on initialization, we can change the token attribute the PhraseMatcher uses when comparing the patterns to the matched Doc.
Let’s say we wanted to create case-insensitive match patterns. We can do so using the attribute LOWER that enables us to match on Token.lower.
Although nlp.make_doc helps us create Doc objects for patterns as efficiently as possible, it can cause issues if we want to match for other attributes. It only runs the tokenizer and none of the other pipeline components. So, we need to ensure that the required pipeline component runs when we create the pattern dictionary.
For example, to match on POS or LEMMA, the pattern Doc objects need to have part-of-speech tags set by the tagger or morphologizer. We either call the nlp object on the pattern texts, or use nlp.select_pipes to run components selectively.
Why PhraseMatcher?
Okay, that’s cool and everything, but why are we choosing PhraseMacher in the first place? Wouldn’t Python’s built-in find() method do just fine? What about spaCy’s Matcher class?
Yeah, both of these approaches will work, but they are rather inefficient.
The time complexity of the find() function is O(N*L) where N is the size of the string in which we search, and L is the size of the phrase(pattern) we are searching for. And this is just for one phrase, so this complexity would increase linearly with the number of phrases as well.
Matcher vs PhraseMatcher
There are two main reasons for choosing PhraseMacther over the Matcher class when working with large lists of patterns:
- computational efficiency
- ease of implementation.
Matcher runs in O(N*M) time for a document of N words and a pattern list of M entries. On the other hand, PhraseMatcher's average-case complexity is much better. The specifics depend on the pattern list, but it's generally somewhere between O(N) and O(N*log(M)). This has a big impact when the phrase dictionaries are very big, i.e., when we have a large M. For instance, let's say we want to match for a dictionary with every drug manufactured by a pharmaceutical company. PhraseMatcher will massively outperform its Matcher equivalent.
Just take a look at this time complexity plot. See how quickly the upper bound for Matcher(purple) moves in comparison to PhraseMatcher(blue) for the same increase in M.
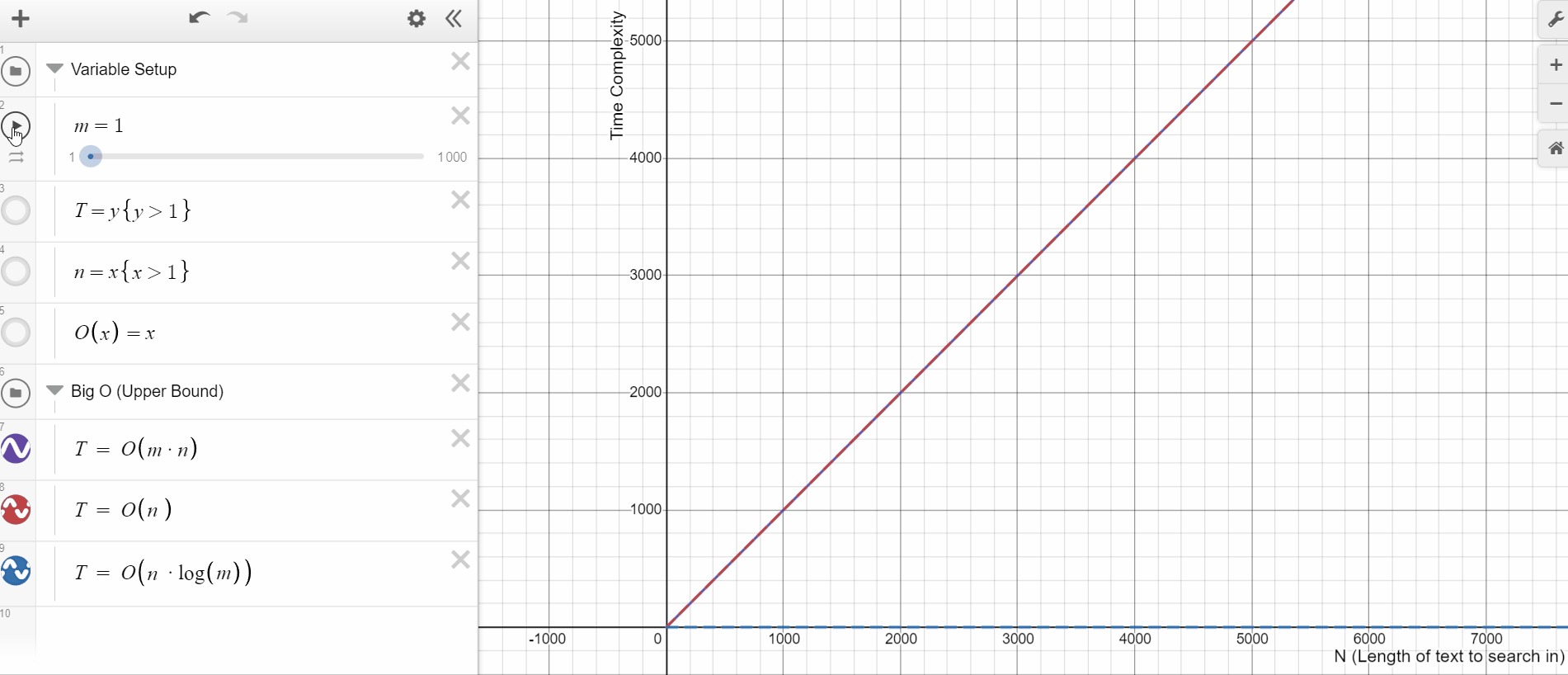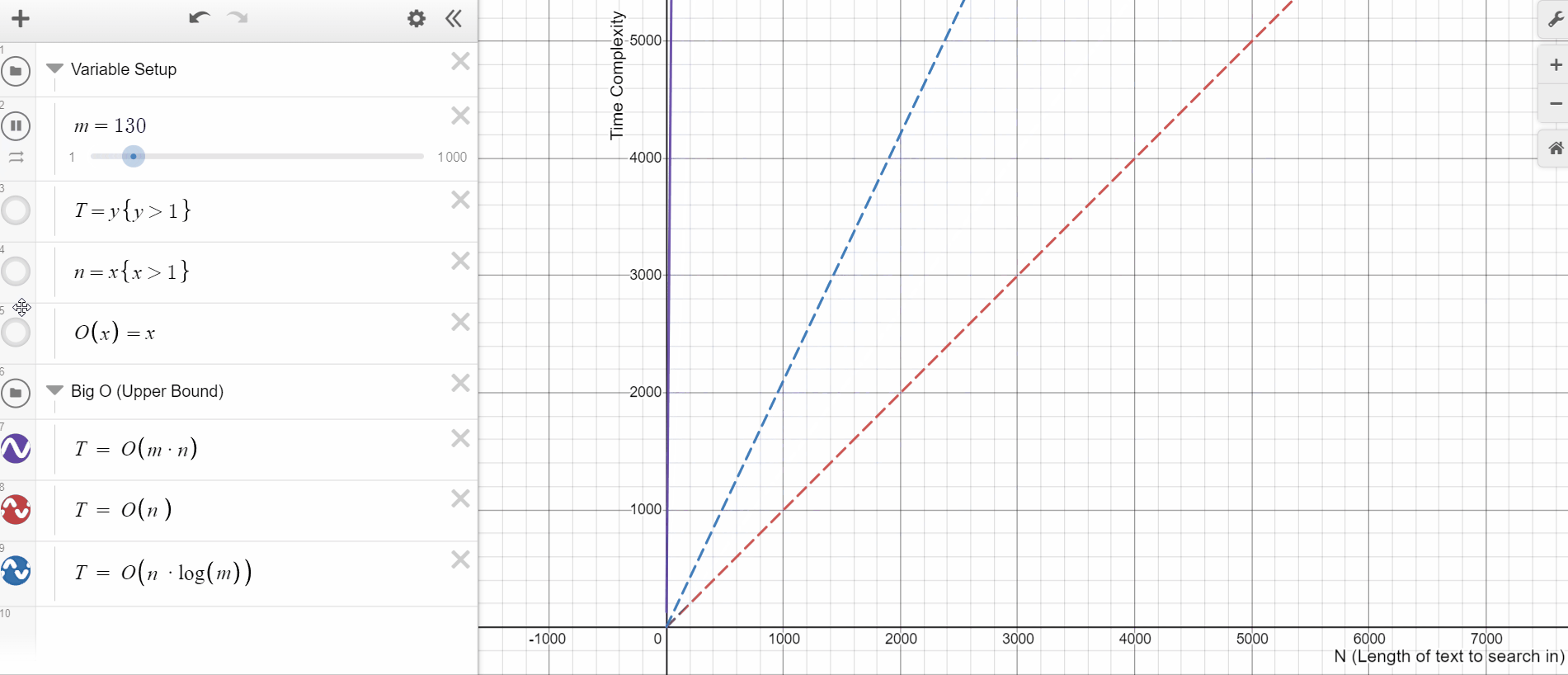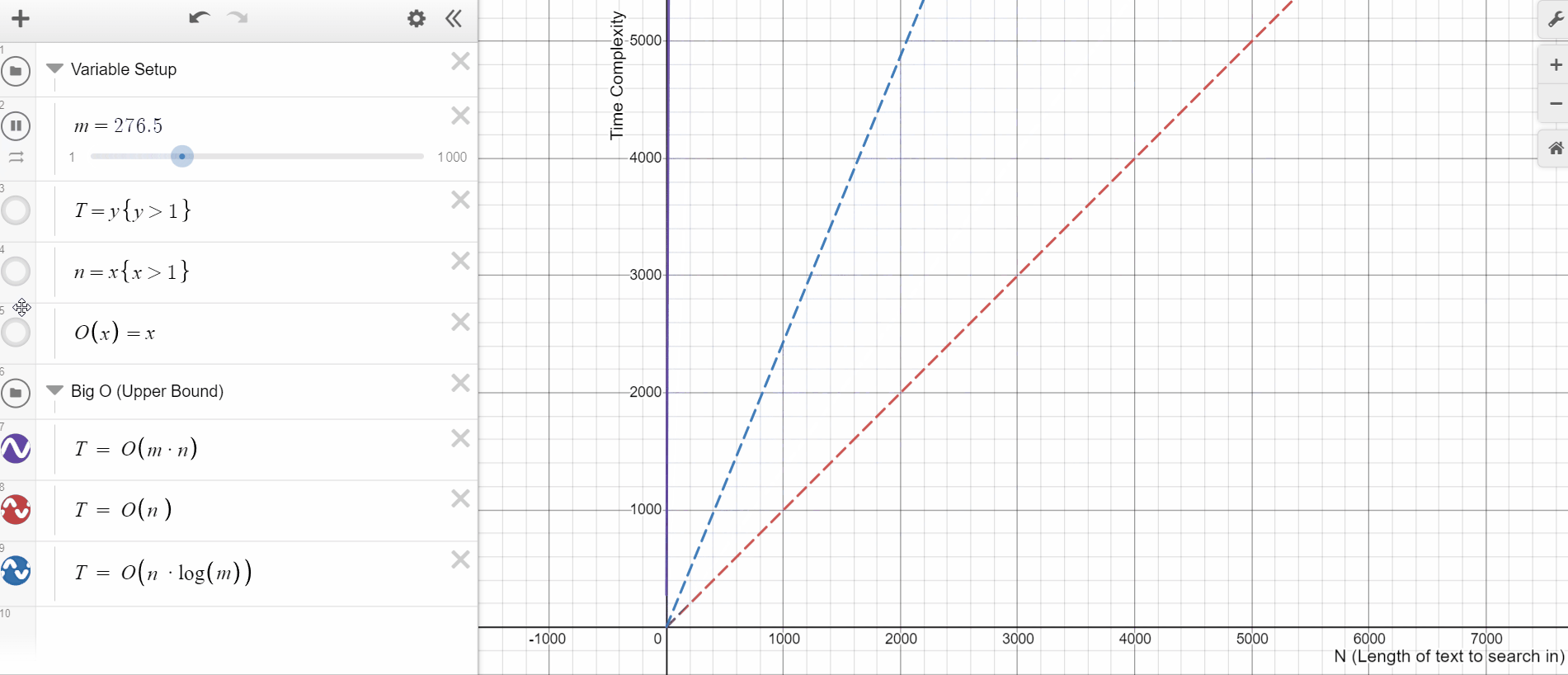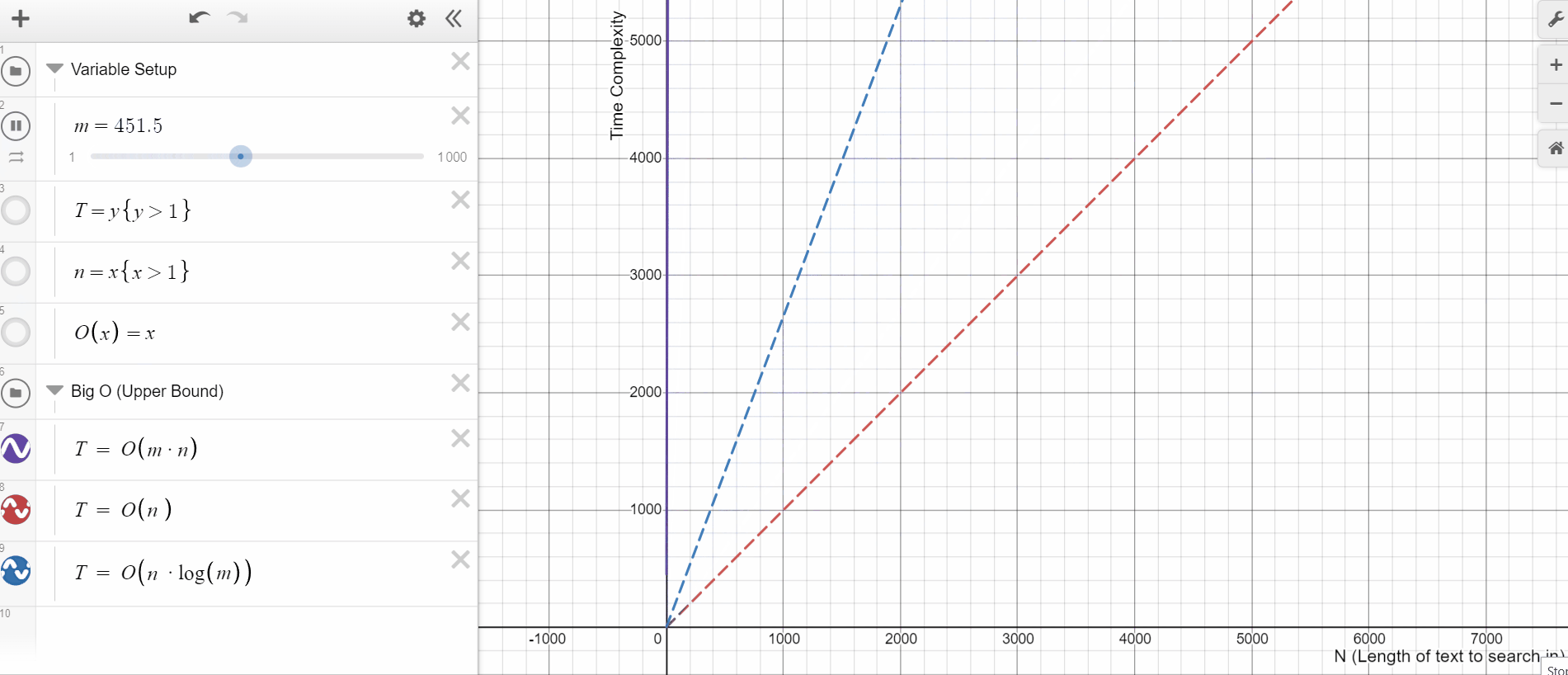
The other advantage of PhraseMatcher is its ease of use. With PhraseMatcher we can easily loop over the list of phrases and create Doc objects to pass as patterns. The process is a bit more complex for a Matcher object as it works on the token level. So we’ll have to accommodate for phrases of different token lengths.
For instance, to match the phrase “Washington, D.C.” using Matcher, we would have to create a complex pattern like the following two:

Whereas, when using PhraseMatcher, we can simply pass in nlp("Washington, D.C.") and don’t have to write complex token patterns.
Using PhraseMatcher To Label News Data
Besides spaCy and pandas, we’ll be using a few other Python libraries:
- cleanco - To clean and normalize company names
- BeautifulSoup and requests - To fetch the list of S&P500 companies from Wikipedia and extract relevant data.
To install these run:
Getting Organization Names And Ticker Symbols
We’ll be using the list of all NasDAQ listed companies available on datahub.
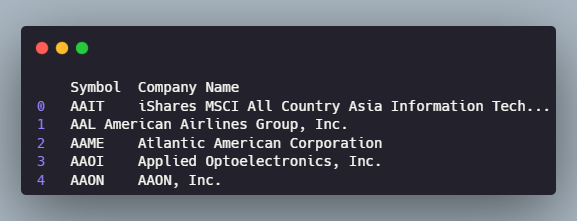
This list was last updated three years ago, so we’ll supplement it using the list of S&P500 companies available on Wikipedia.
Get the webpage with the table of S&P500 companies.
Parse the HTML using BeautifulSoup and select the required table.
Convert the HTML table into a Pandas DataFrame using the read_html() method
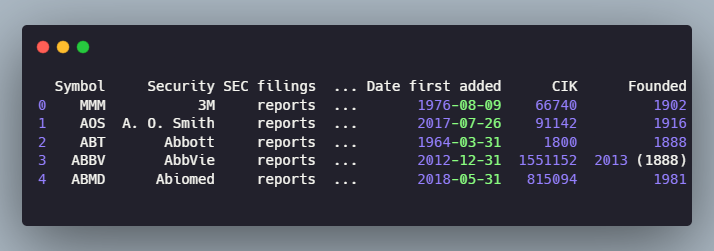
There are some extra columns that we don’t need, and the name for the organizations’ column is different from the other DataFrame. We’ll drop the extra columns and rename the ‘Security’ column.
Now we can combine the two tables to get a more comprehensive list of names and tickers.
Cleaning Organization Names

Some of the organization names have additional information in parentheses such as the state of registration or the class of the share. These things don’t matter for our aim of labeling organization names. So let’s create a function that removes anything enclosed with a pair of parentheses.
Besides that, organization names can have multiple forms. For example, Activision can be written as just ‘Activision Blizzard’ or ‘Activision Blizzard, Inc.’. Currently, our list contains the longer form of the names, to create a robust annotation system we’ll need to include both forms.
To obtain the cleaner, shorter versions of the organization names we’ll use cleanco
There are a few empty entries, so let’s deal with that before we move further.
Moreover, there are some incomplete/wrong organization names that will cause false positives if they're not dealt with.
Create The PhraseMatcher Labeller
Now that we have all the data we need, we can create our PhraseMatcher object.
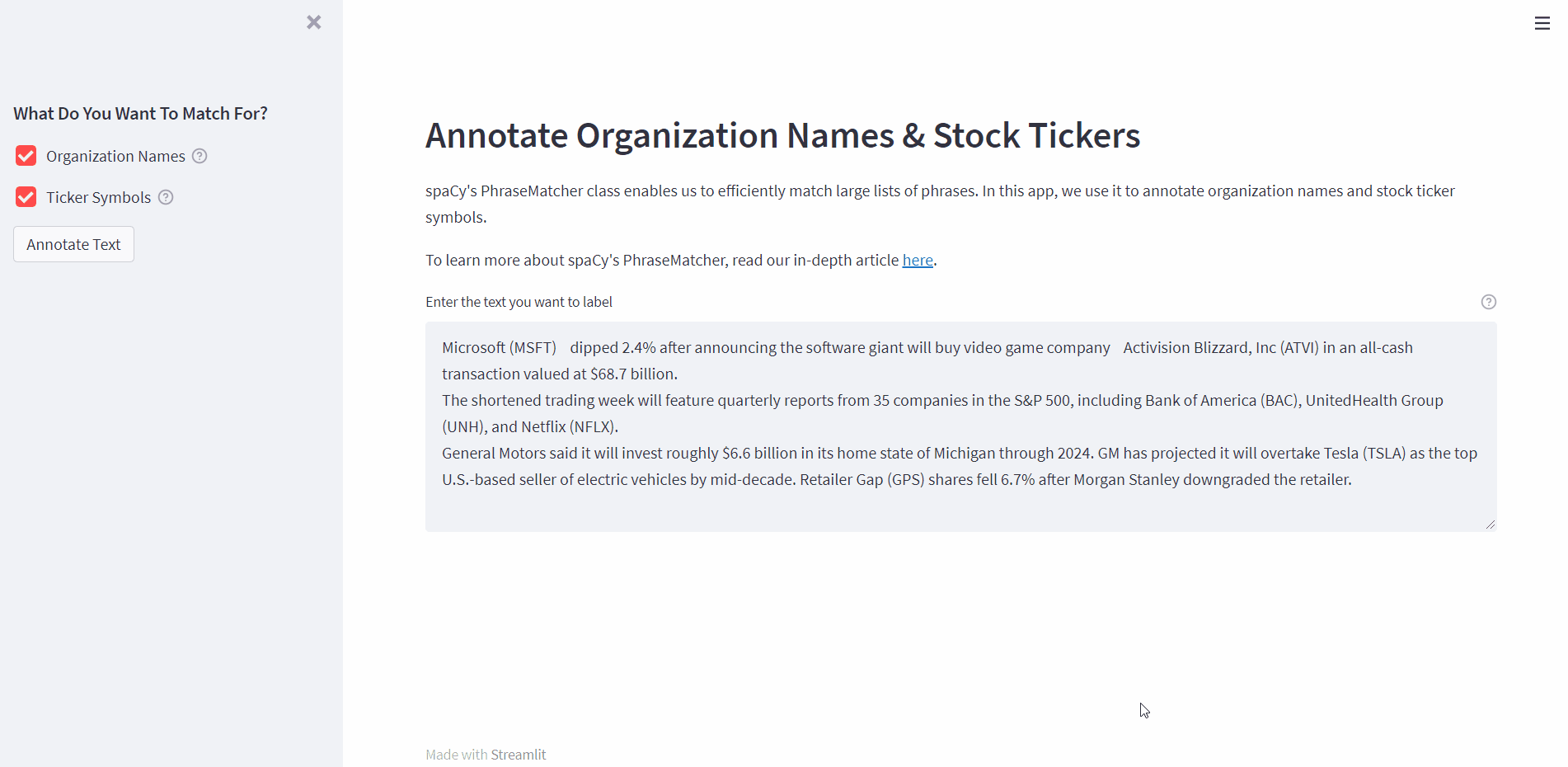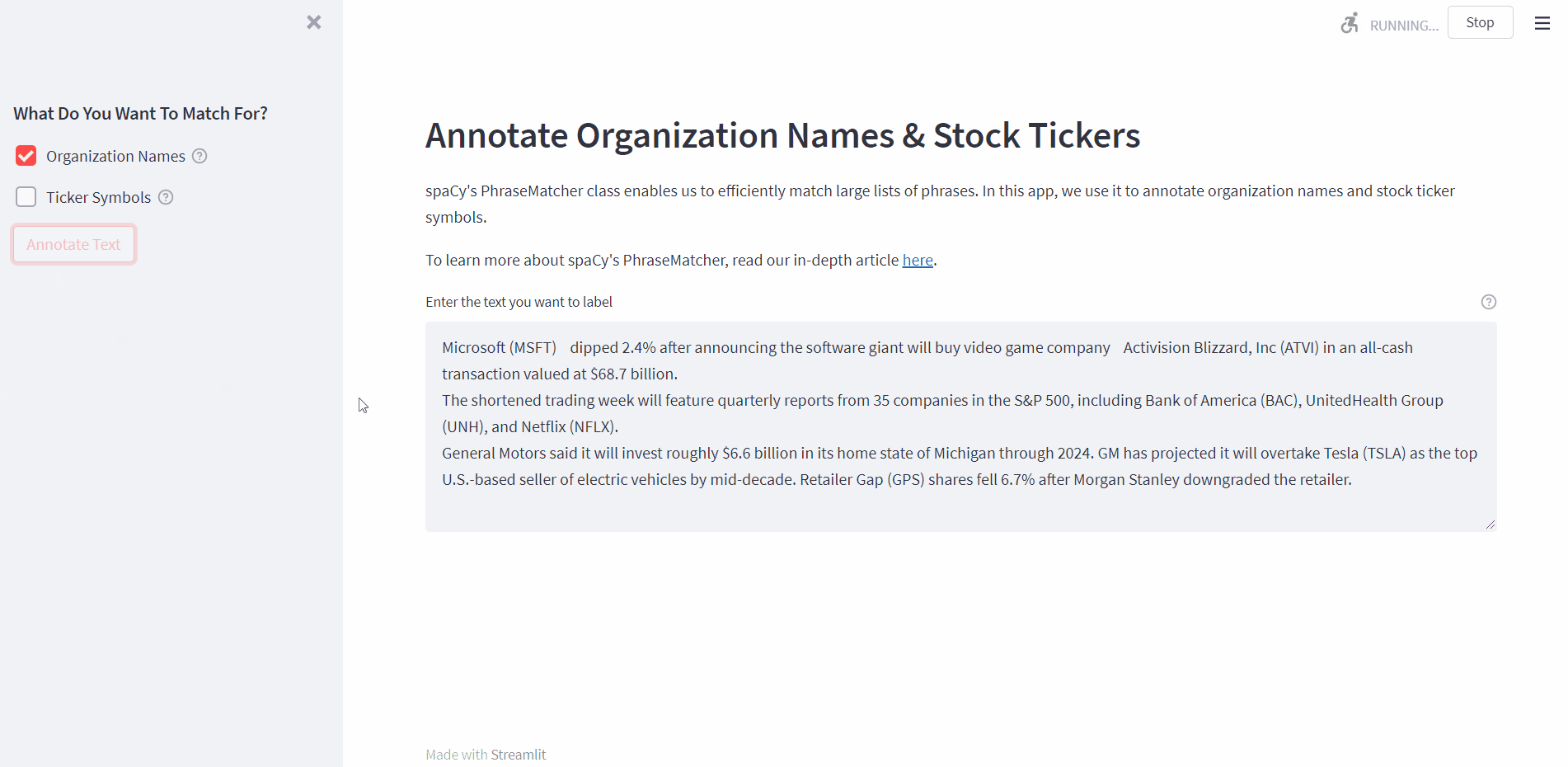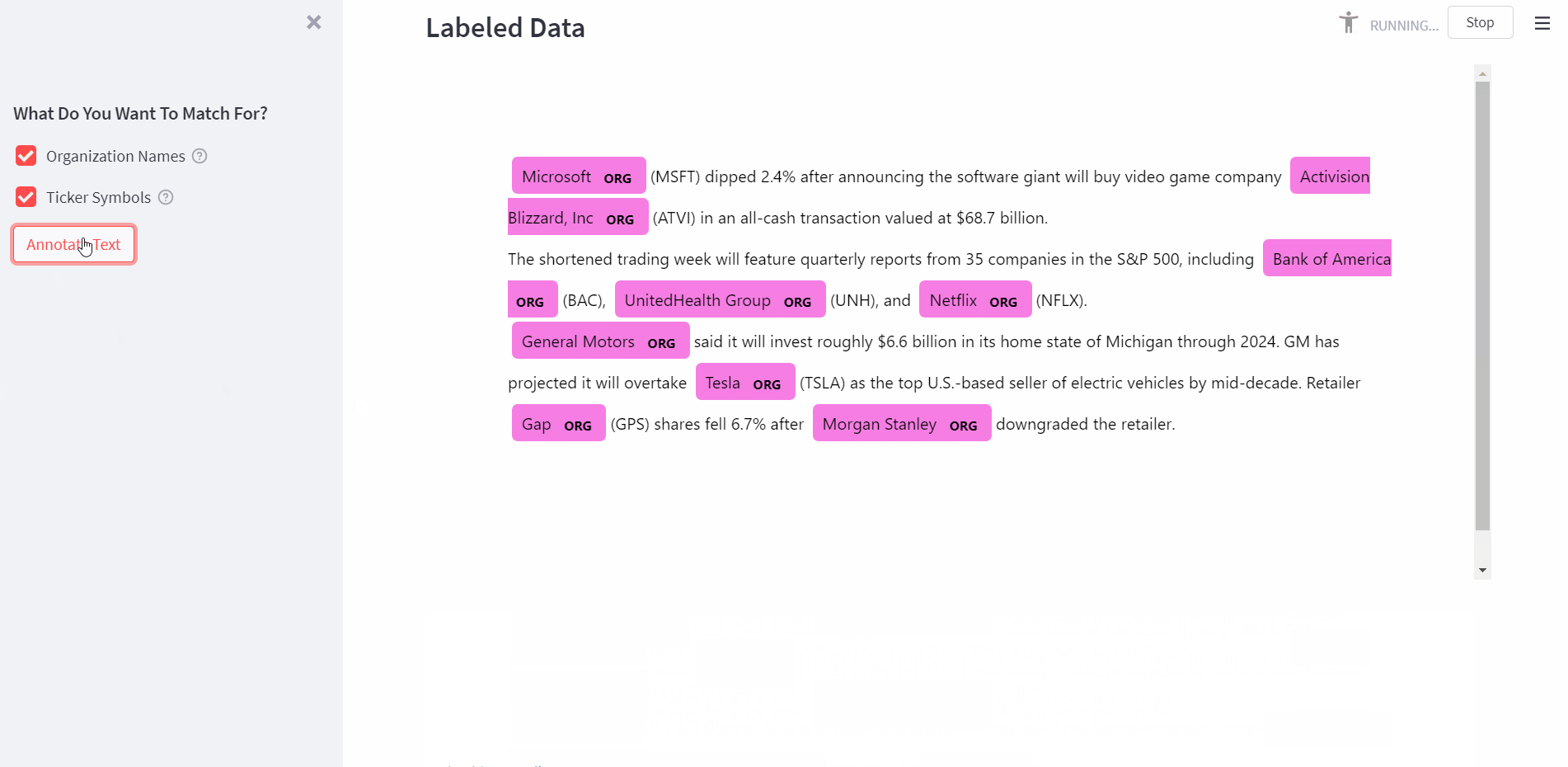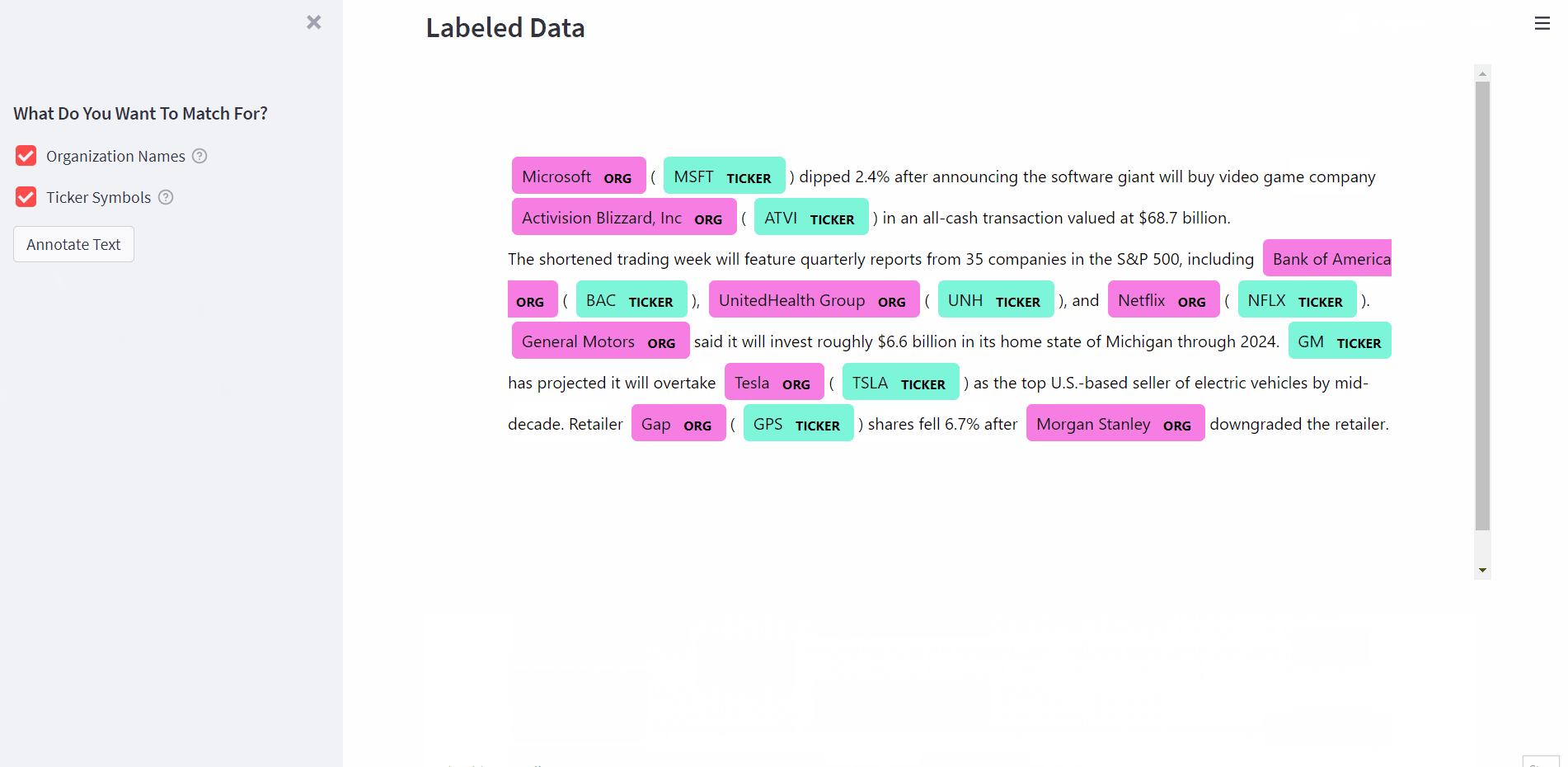
PhraseMatcher supports adding multiple rules containing several patterns, and assigning IDs to each matcher rule. This means we can use the same matcher object for the names and tickers.
And that’s it! Now we can use this to label text data. Let’s try it out on some news data and see how it performs.
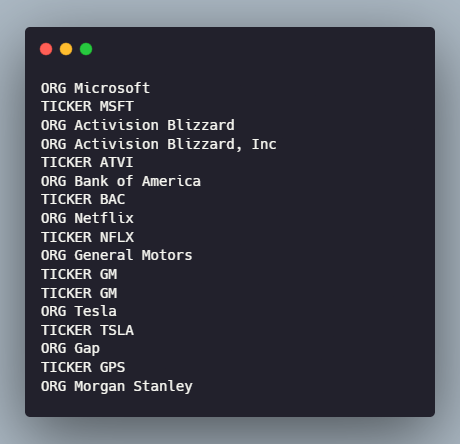
Hmm, where seems to be some duplication. The problem is that our PhraseMatcher finds both forms of the company name, the longer complete version, and the shorter, cleaner version. There’s a fairly straightforward (greedy) solution to this issue, we count the occurrences of each matched name in all matched names.
The idea is that shorter names like “Activision Blizzard” will have a count of more than one. This is because they will as they will also appear as substrings in longer names like “Activision Blizzard, Inc”. But the longer version will occur only once. Let’s add this de-duplication and visualize the results using spaCy’s displacy.
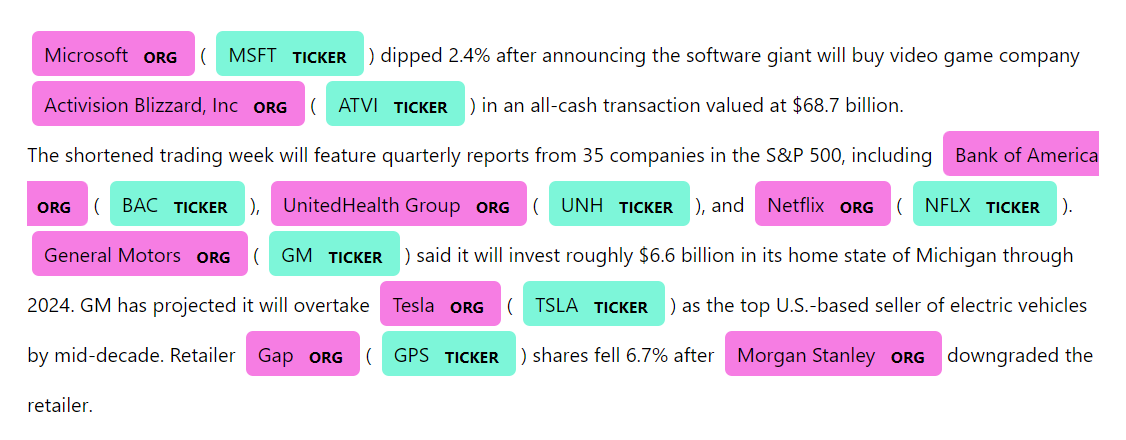
Conclusion
In this article, you learn about spaCy’s PhraseMatcher and used it to create a rudimentary text annotation pipeline that labels organization names and their ticker symbols. Depending on your needs, this pipeline can be easily extended to offer near-perfect results. You can even supplement it with a statistical NER model.
Generally speaking, statistical models are useful if your application needs to be able to generalize based on the context. That being said, you should always carefully consider if your use case really needs a model. Sometimes it might be better off with a rule-based system.
Two main criteria for choosing a rule-based approach:
- You already have a large dictionary of terms to match
- There’s a more or less finite number of instances of the given category (public-traded organization names and cities are good examples)
Combining a rule-based system with a statistical NER model might help you get better results if misspellings and spelling variations are important for your application. And spaCy’s entity recognizer respects pre-defined entities (e.g. set by previous ) and will use them as constraints for its predictions. So, if you train a NER model to detect public traded companies and add it after the rules, it will only find entities in the text that hasn't been labeled. This can potentially help you find entities the rules might miss.







































