





















Learn to write an information extraction NLP pipeline using spaCy’s Matcher. It will extract dividend information from news headlines and articles.
By the end of this article, you will be able to write an information extraction NLP pipeline using spaCy’s Matcher. It will extract dividend information from news headlines and articles.
You should be interested in this article if you like algorithmic trading and stock screening using Python. Mining unstructured text data for insights is what could set your algorithm apart.
Demo:
For the scope of this article, we will use only rule-based techniques to see how much could be done with it.
In this tutorial, we will:
- Get introduced to the fundamentals of rule-based matching using spaCy’s Matcher
- Use what we learn to create an information extraction NLP pipeline
spaCy Matcher vs Regular Expressions
Pattern matching forms the basis of many artificial intelligence solutions, especially so for natural language processing (NLP) tasks. Regular expressions (RegEx) are a powerful construct for extracting information from text, but they are limited to string patterns.
spaCy’s rule-matching engine Matcher extends RegEx and offers a novel solution to all our pattern matching needs. Compared to regular expressions, the matcher works with `Doc` and `Token` objects not just strings. It’s also more flexible, we can search for textual patterns, lexical attributes, or use model outputs like the part-of-speech (POS) tags or entity type.
Beginners Guide To spaCy Matcher
First, install spaCy.
The first step is to initialize the Matcher with a vocabulary. The matcher object must always share the same vocabulary with the documents it will operate on.
Once the matcher object has been initialized with a vocab, we can add patterns to it using the matcher.add() method. This method takes two arguments: a string ID and a list of patterns.
Let’s say we want our matcher object to find all variants of “Hello World!”:
We need to match for three tokens:
- A token with the text “hello” in upper or lower case.
- A token with the text “world” in upper or lower case.
- Any punctuation like “.” or “!”.
The pattern is defined as a list of dictionaries, where each dictionary represents one token. For our “hello world” matcher we define the pattern as:
Here, the `LOWER’ and `IS_PUNCT` keys correspond to token attributes. `LOWER` matches for the lowercase form of the token text and `IS_PUNCT` is a flag for punctuations.
The `OP` key is a quantifier. Quantifiers enable us to define sequences of tokens to be matched. For example, one or more punctuation marks, or specify optional tokens with `?`. We use it here to match for one or more punctuations.
When a matcher object is called on a Doc, it returns a list of (match_id, start, end) tuples.
Here, match_id is the hash value of the string ID and can be used to retrieve the string from the StringStore, and the start and end correspond to the span of the original document where the match was found.
Besides the obvious text attributes such as `IS_ALPHA`, `IS_DIGIT`, `IS_UPPER`, and `IS_STOP`, we can use the token’s part-of-speech tag, morphological analysis, dependency label, lemma, or shape. Find the full list here.
spaCy Matcher With Lemma
For instance, if we wanted to match for the different forms of a verb like run, we could do so using the `LEMMA` attribute.
Instead of just mapping token patterns to a single value, we can also map them to a dictionary of properties. For example, we can match the value of a lemma to a list of values, or match tokens of a specific length.
spaCy Matcher With RegEx
Even with all these nifty attributes, sometimes, working on the token level is not enough. Matching for spelling variations is an obvious example, for these cases, the `REGEX` operator enables us to use regular expressions inside the Matcher.
When To Use spaCy Matcher?
The matcher will work well if there’s a finite number of examples we want to find in the text. Or if there’s a very obvious, structure pattern that we can express with token rules or RegEx. It is a good choice for things like dates, URLs, phone numbers, or city names.
For complicated tasks, a statistical entity recognition model would be the better choice. But they have their own caveat, a large amount of training data is required to train robust models. Rule-based approaches enable us to create a prototype of the statistical model while gathering and annotating the training data. We can also combine the two approaches to improve a statistical model with rules by using the EntityRuler. This helps handle very specific cases and boosts accuracy.
Here’s a nifty tool for visualizing and playing with matcher patterns: Rule-based Matcher Explorer
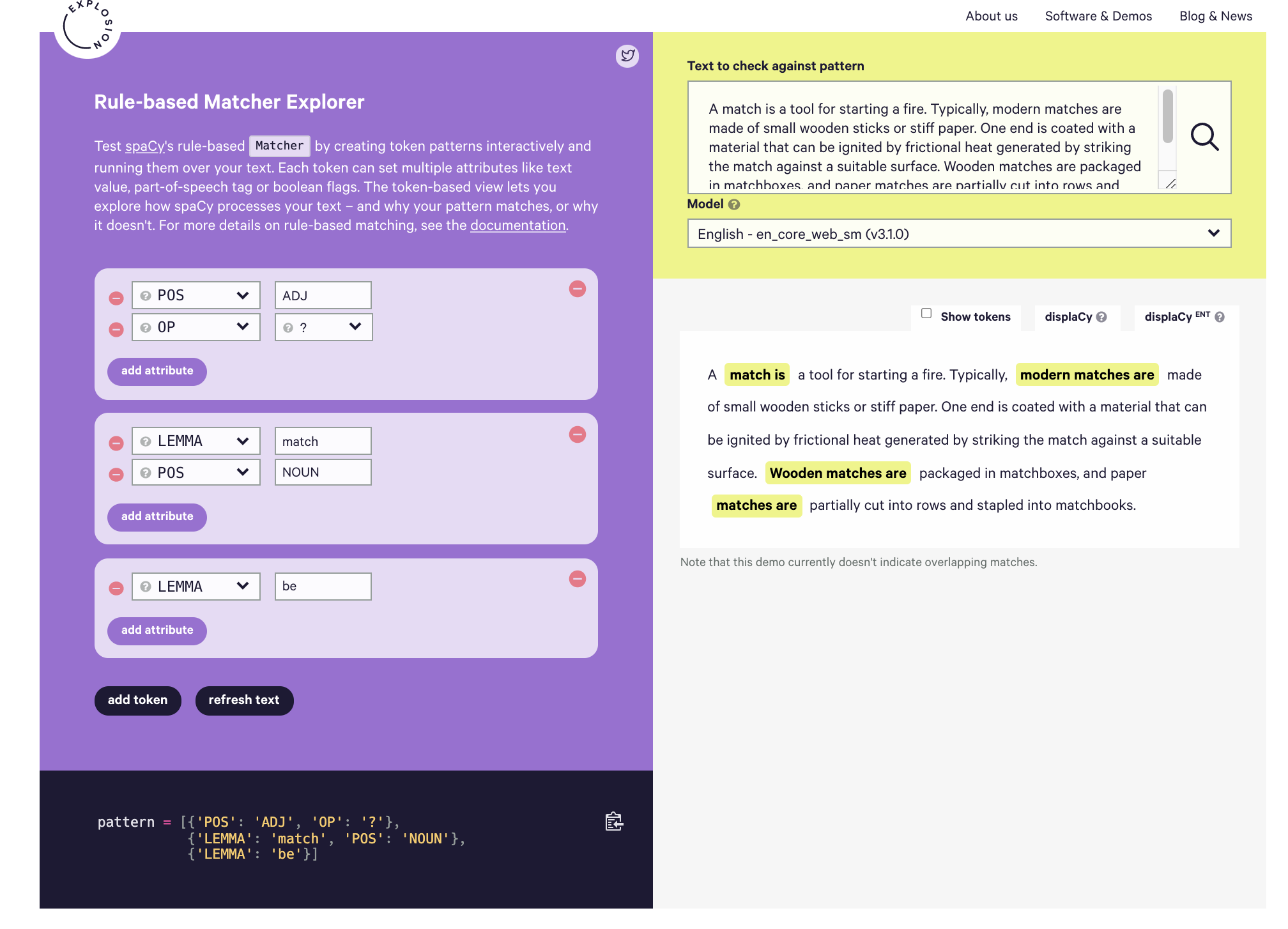
Using spaCy Matcher To Extract Dividend Information From News Headlines
Loading packages and the dataset we'll work with.
We will be using a JSON file of news articles from top publications fetched from the newscatcherapi using the query “dividend”.
You can get the data for this article via this link.
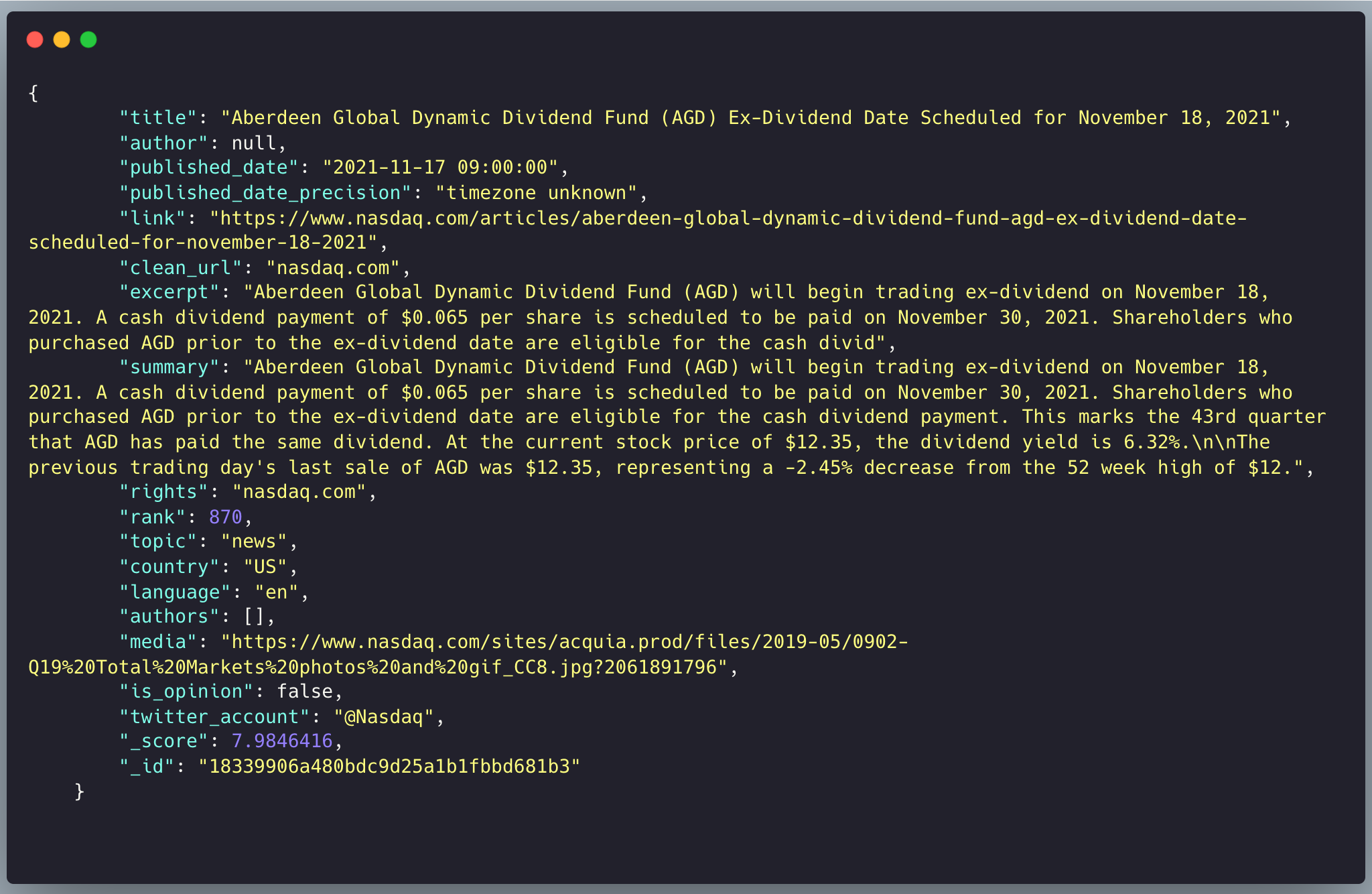
There’s a lot of information here but we’ll focus on the headlines and the article summaries. Let’s look for common patterns in the headlines of the articles.
There are a lot of article headlines in the following formats:

The first thing we’ll make a pattern for is the organization names. Using the string patterns alone won’t be enough so we will need to incorporate part-of-speech(POS) tags as well.
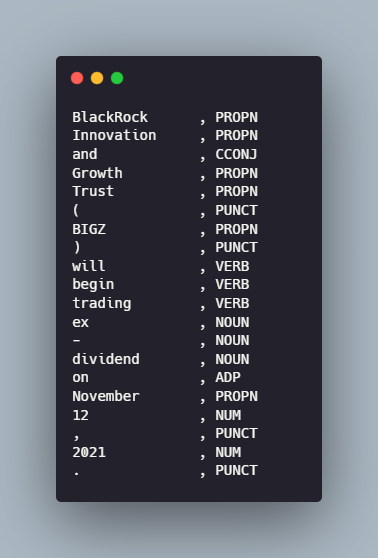
The organization name tokens consist of proper nouns with optional conjunction like “and”. Another thing to note is that the organization name is often followed by an “ ‘s” or simply “ ‘ “ in the case of the second headline type. This means that we don’t necessarily have one concrete way of finding the end of the organization's name, so we will rely on the presence of the ticker after it.
Detect Organization
Before we create our first matcher object and initialize it with the organization name pattern, we’ll need to initialize it the vocabulary of the nlp object.
This matcher object finds all the organizations in the two headline types. But the problem is that it returns all possible sequences of tokens that fit the pattern. And since the pattern has a bunch of optional tokens it will return some half-complete organization names.

There’s a simple way to fix this problem. We check if the Matcher object returns more than one match, if it does we choose the longest match. And if it only returns one match, well then, that’s our organization name.
Another thing to keep in mind is that our matches will include the open parentheses( “(“ ) of the ticker so we’ll have to slice our matches accordingly.
Detect Ticker
The next easiest pattern to extract is the stock ticker. It is enclosed within a pair of parentheses and may or may not have information about the exchange it’s listed on. The tickers exist in the following two formats:
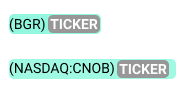
Let’s test these two pattern matching methods on a headline:
Detect Date and Amount
Now depending on the headline type, we can extract two more bits of information:
- the ex-dividend date
- the dividend amount
Let’s do the dividend amount first. We could use the dollar sign alone to fetch the amount but there are often other monetary amounts, like the total dividend earned by a firm.

So we will use the presence of “US” before the dividend amount to work around this confusion.
as we saw earlier, the ex-dividend date has a defined format and the month is a proper noun.

Using this information we can come up with a simple pattern.
The articles with ex-dividend date headlines have the dividend amount and payment date in a consistent format in the summary. We can easily create two more Matcher objects to extract these bits of information.

The payment date has the same format as the ex-date. This is good and bad. Good because we already have a working pattern for it, bad because our existing matcher won’t be able to differentiate between the two dates.
One quick workaround is to use the neighboring text to differentiate the two, namely the presence of “paid on” before the payment date. Since we are matching extra text on either side of the relevant information, we will have to modify the final match index.
Using the same logic, we can extract the dividend amount per share based on the presence of the text “per share” after the dollar amount. We are doing this to avoid mistakenly extracting the total amount of dividend a company is distributing.

Again, we are using extra neighboring text in our Matcher so we will adjust the indices.
Final Pipeline
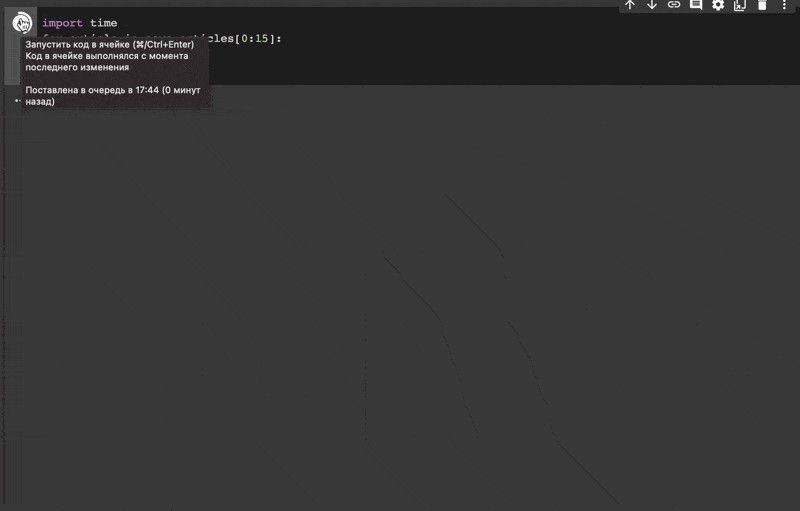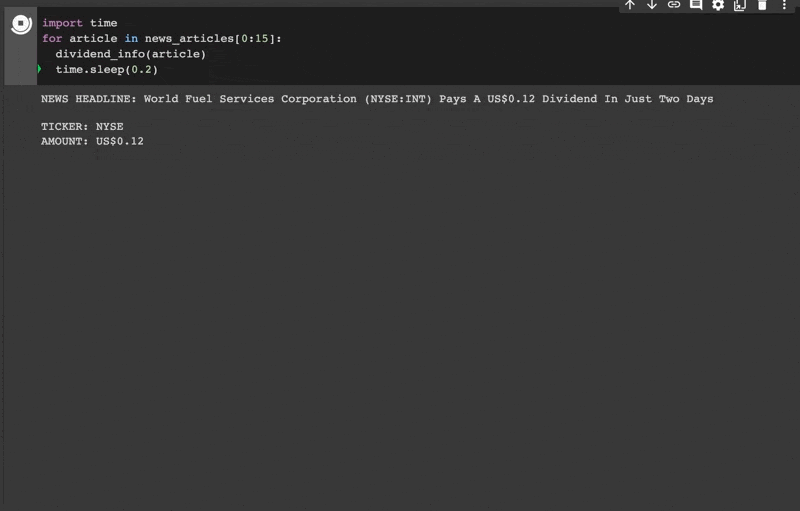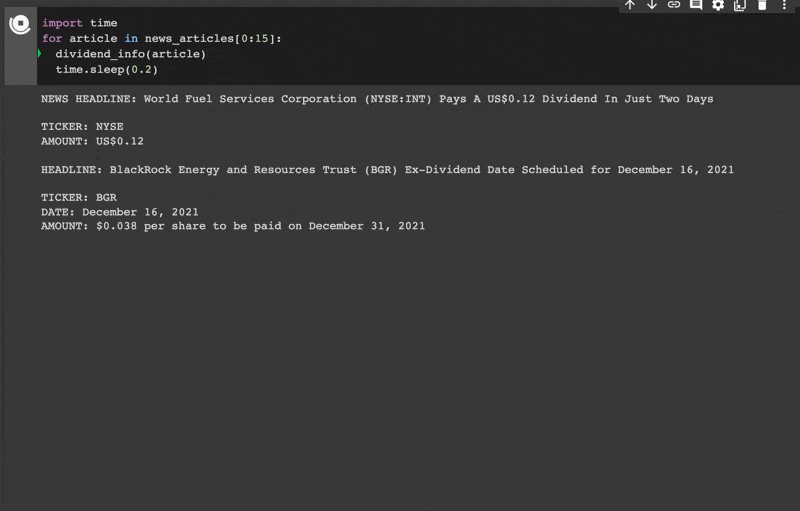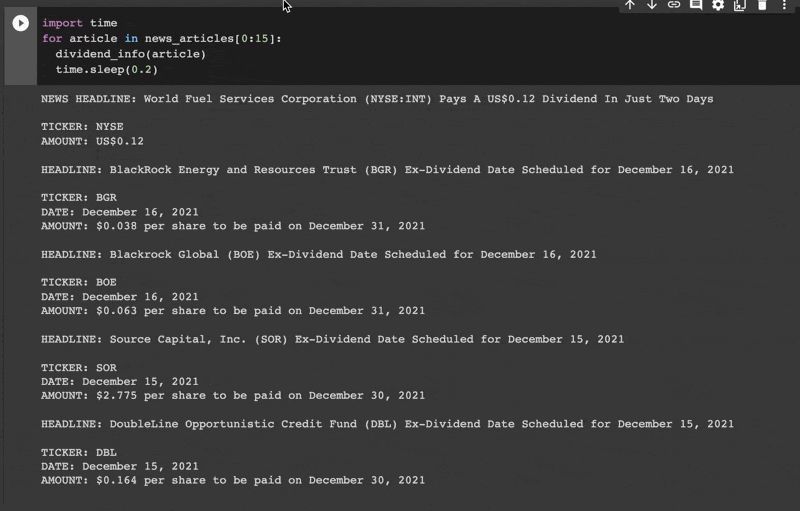
Let's test these patterns
We now have all the Matcher methods we need to extract dividend information. Let’s combine these into one function so we can easily test it on our news data.
Conclusion
In this article, you learned the basics of spaCy’s Matcher class. Then used this newfound knowledge to create a robust information extraction pipeline for news articles. You can now extend the patterns to extract dividend information from more types of articles or change them to extract other types of information altogether.





































