





















Rigorous benchmark of NewsCatcher CatchAll vs Exa Websets, Parallel AI FindAll, and OpenAI Deep Research across 35 real-world queries. See why CatchAll achieves 5x better recall with 77% higher F1 scores for comprehensive event discovery.
We built CatchAll, a web search API, to address a problem that traditional search tools struggle with: recall.
When we tell people that CatchAll finds 5x more relevant events than competitors, the natural question is: “Can you prove it?”
This is the complete story of how we benchmarked CatchAll against Exa Websets, Parallel AI FindAll, and OpenAI Deep Research using 35 real-world queries, rigorous evaluation methodology, and transparent reporting of limitations.
Why We Did This
The architectural bet: CatchAll’s design optimizes for recall (finding more relevant events) over precision (showing only perfect results). The more common approach in the market prioritizes precision—returning a smaller, highly filtered set of results to maximize accuracy. This works brilliantly for traditional web search (“show me the top 10 articles about AI”) but fails for comprehensive event detection (“find all AI acquisitions in December”).
The skepticism: Early customers questioned our approach: “So you’re trading precision for recall? How do I know the extra results are worth sifting through?”
The commitment: We built a rigorous, reproducible evaluation framework to answer this with data, not claims:
- Test against real competitors using real queries
- Use objective metrics, not cherry-picked anecdotes
- Be transparent about limitations and failures
- Be re-runnable as we improve
Evaluation Methodology
Query Design: 35 Real-World Questions
We crafted queries reflecting actual business use cases: market intelligence (“Catch all AI acquisitions Dec 1–7, 2025”), regulatory monitoring (“Catch all product recalls Dec 1–7, 2025”), risk detection (“Catchall data breaches Dec 1–7, 2025”), and labor tracking (“Catch all labor strikes Dec 1–7, 2025”).
Each query specified exact time periods (7-14 days, adjusted to 1-3 days for high-volume topics), creating a reproducible snapshot that we could periodically retest.
Providers and Configuration
We tested CatchAll, Exa Websets, Parallel AI, and OpenAI Deep Research. Each was configured to return maximum results—this is event discovery comparison, not search ranking.
Metrics That Matter
Core definitions:
- TP (True Positives): Relevant events correctly identified
- FP (False Positives): Irrelevant results returned
- FN (False Negatives): Relevant events missed by one provider but found by competitors
Precision: Of the returned results, what percentage were relevant?
Observable Recall: Of all relevant events found by ANY provider, what percentage did each provider find?
where FN = unique events found by competitors that evaluated provider missed.
F1 Score (Primary): Harmonic mean of precision and recall.
Critical limitation: We measure "recall within observable universe" (events found by at least one provider), not absolute recall (all events that occurred). If 500 AI acquisitions happened, but tools found 329 combined, our recall is based on 329. True recall might be lower for all providers.
This limitation remains valid because it affects all providers equally. The relative comparison (CatchAll’s 86.8% vs Exa’s 16.9%) remains meaningful—CatchAll finds 5x more events within the same observable universe.
LLM-as-a-Judge Evaluation
To calculate metrics, we distinguish True and False Positives—relevant and irrelevant results. Initial manual checks involved team members tagging relevance. We then fine-tuned a large LLM model, achieving 92% accuracy compared to manual tagging.
Deduplication
Without effective deduplication, high recall is meaningless—the same event repeated 50 times provides no value. We tested three approaches:
- Embeddings + clustering: ~60-70% accuracy—too many duplicates slip through
- Pure LLM comparison: Accurate but O(n²) prohibitive for large result sets
- Iterative LLM with keyword grouping: 95%+ accuracy, manageable cost
Winner: Group records by keywords, compare within groups using Claude Opus 4.1, then iteratively refine. Our 94.5% uniqueness rate proves this approach works.
Cross-provider deduplication: After deduplicating within each provider, we ran a second pass across all providers to identify when different tools found the same event. This gives us unique_tp_total (3,755)—the denominator for fair recall calculation.
Our results: Across 35 queries, CatchAll achieved 94.5% uniqueness—higher than Exa (71.5%) and Parallel AI (67.6%), though slightly behind OpenAI Deep Research's 97.4%. This proves that high recall doesn't require tolerating duplicates.
Fairness: URL Enrichment
CatchAll fetches full content from our 2B article index. Competitors return URLs. To evaluate fairly, we enriched competitor URLs via NewsCatcher APIs (search by URL → parser fallback). When enrichment failed, we “forced” results to true positives to avoid unfair penalization.
Key point: This is an evaluation methodology advantage, not a product feature. In real-world usage, competitors return results that users can access directly.
Reproducibility
Frozen period: November 20 - December 7, 2025. We’ve built an automated pipeline to re-run quarterly with updated results.
Results
Overall Performance
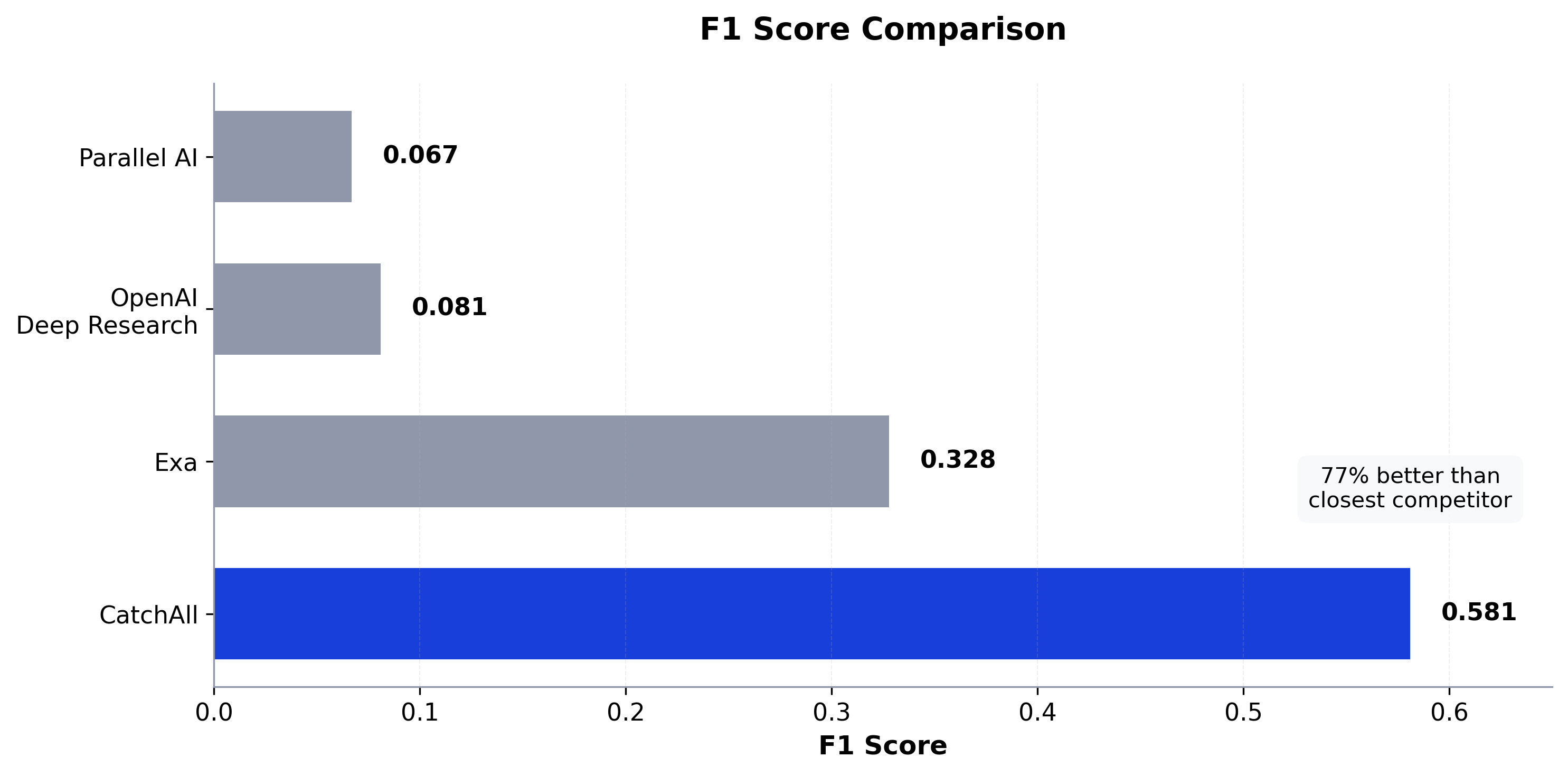
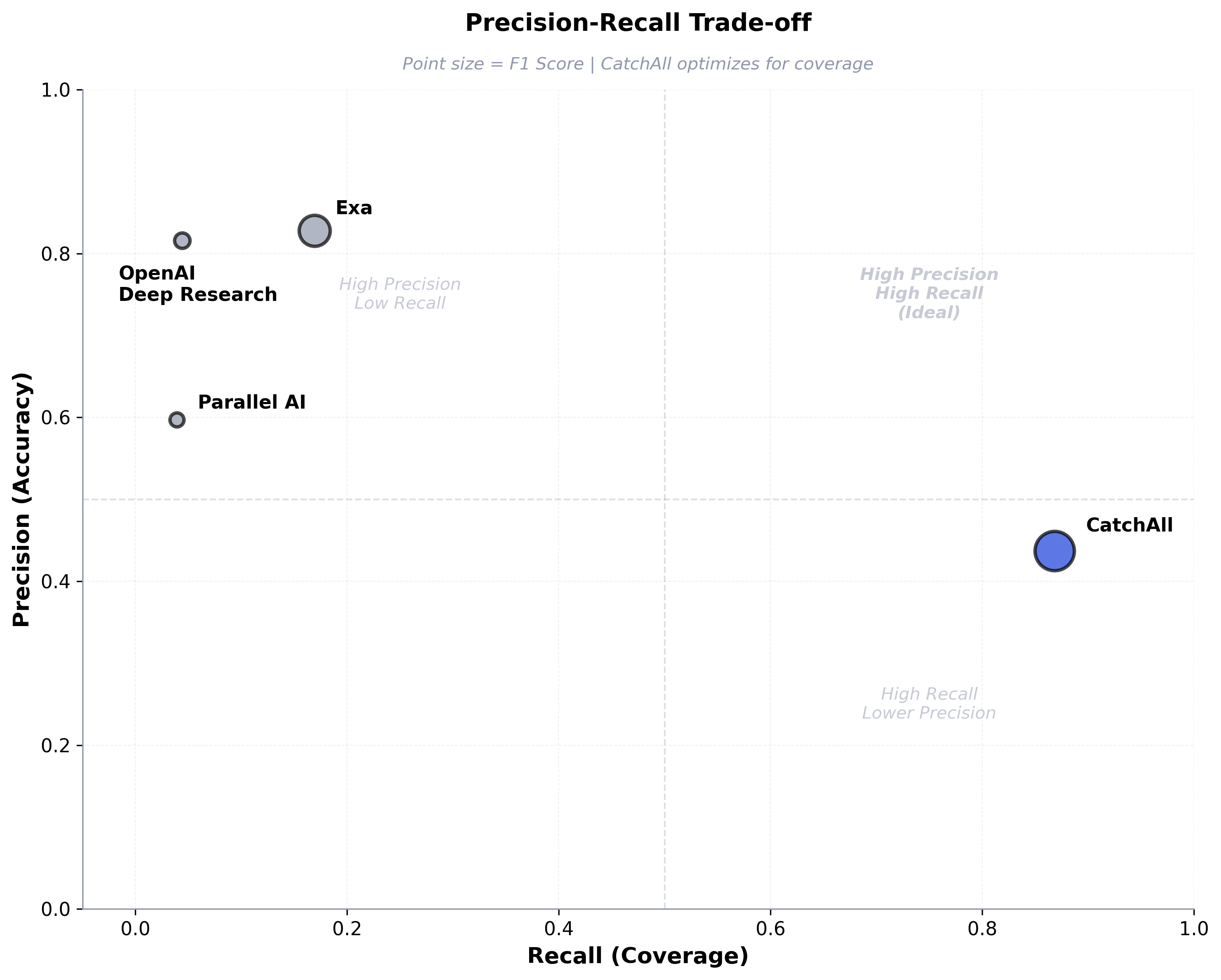
CatchAll wins 71% of queries with 77% better F1 than Exa. Observable recall of 86.8% means we find 5 out of 6 relevant events, while Exa finds 1 out of 6.
Coverage Analysis
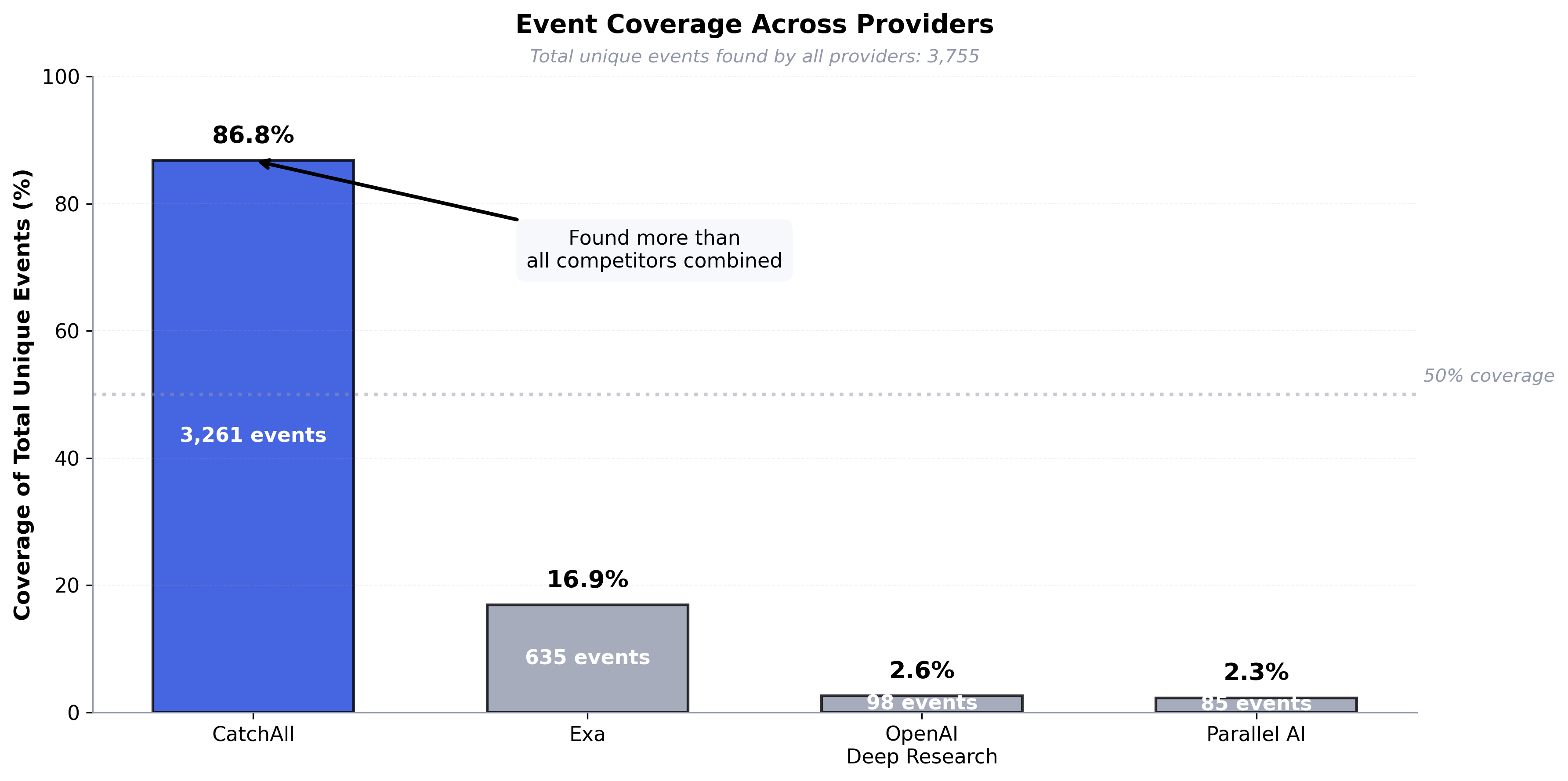
Across 35 queries, providers found 3,755 unique events total:
- CatchAll: 86.8% (3,261 events)
- Exa: 16.9% (635 events)
- OpenAI: 2.6% (98 events)
- Parallel AI: 2.3% (85 events)
CatchAll found more events than all competitors combined. In 66% of queries, we achieved more than twice the recall of our best competitor.
Query Examples
1. AI Funding (High Volume)
“Find all funding of AI products or AI-oriented companies between Dec 1-7, 2025.”
CatchAll found 4.5x more funding events.
2. Labor Strikes (Global)
“Find all labor strikes announced between Dec 1-7, 2025.”
Near-complete coverage (99.2%)—found 35x more events.
3. Product Recalls (Regulatory)
“Find all product recalls announced between Dec 1-7, 2025.”
High recall (94%) AND high F1 (0.821)—balanced performance.
4. Taiwan Workplace Accidents (Where Exa Wins)
“Find all workplace accidents in Taiwan between Nov 24 - Dec 7, 2025.”
Exa wins on small, geographically specific queries where precision matters more than coverage.
5. Data Breaches (Security)
“Find all data breaches disclosed between Dec 1-7, 2025.”
For security monitoring, missing 95% of breaches is worse than filtering false positives.
What We Learned
1. Architectural Trade-offs Are Design Choices
The numbers reflect our design philosophy: CatchAll’s 86.8% observable recall comes at 43.7% precision cost. Competitors achieve 60-80% precision with 2-25% recall. Neither is wrong—they solve different problems.
When building databases of M&A, funding, or regulatory events, comprehensive coverage with noise beats perfect top-10 results with massive gaps.
Exception: For small result sets, geographically specific queries, or automated trading where false positives are costly, Exa’s precision-first architecture excels.
2. Query Design Reveals Product Fit
Our queries were structured event detection with clear boundaries: “Find all layoffs involving 50+ employees in the US between Dec 1-7, 2025.” This is CatchAll’s target use case. For narrative synthesis or exploratory research, different tools win.
3. Evaluation Methodology Matters
CatchAll had 0.1% forced TPs; competitors had 40-70%. Why? CatchAll fetches content from our 2B index. Our competitors return URLs we had to enrich via NewsCatcher APIs (failed 40-70% of the time). We forced failed enrichments to true positives to avoid unfair penalization.
The Bottom Line
CatchAll isn't universally better — it's better at comprehensive event discovery, trading precision for recall. In beta, this reflects our belief that missed events are harder to recover than to filter out false positives.
The numbers:
- 60% better F1 score (0.581 vs 0.328)
- 5.1x better observable recall (86.8% vs 16.9%)
- 71% query win rate (25 out of 35)
- 86.8% coverage of all events found
- 94.5% uniqueness rate (clean, deduplicated results)
When to use CatchAll:
- Building databases of M&A, funding, regulatory filings, incidents
- Monitoring broad-scope topics (global events, multiple industries)
- Missing events is worse than filtering false positives
When to use competitors:
- Small result sets with high precision requirements (Exa)
- Narrative synthesis over structured data (OpenAI Deep Research)
- Entity-specific research with validated matches (Parallel AI)
- Top-10 quality results are sufficient
Ongoing Evaluation & Transparency
This evaluation represents November-December 2025, using CatchAll v0.5.1. As all tools improve, results will change.
Our commitment:
- Quarterly re-evaluation: Re-run these 35 queries and publish updated results
- Expanded coverage: Add new queries and competitors as the space evolves
- Open methodology: Full query list and raw results available upon request
- Honest reporting: Report when competitors improve and when CatchAll regresses
Where we're improving:
Precision improvements are more straightforward than recall gains—better validation models and refined extraction prompts reduce false positives without touching our coverage architecture. We're working on both. Next quarter's numbers will show whether we can maintain 86.8% recall while closing the precision gap.
Try It Yourself
Run your own queries and see if CatchAll’s recall-first approach works for your use case.
- 2000 free credits to start
- Full access to monitoring and webhooks
- Compare results with your current tools
Questions about the methodology? Email us at support@newscatcherapi.com
Found an error or have suggestions? We’re committed to rigorous, honest evaluation. If you spot issues with our methodology or want to propose additional tests, please reach out.
Last updated: February 4, 2026 | Evaluation period: November 20 - December 7, 2025 | CatchAll v0.5.1



































