How we built a recall-first search pipeline that processes 50,000 web pages in 15 minutes
50,000 Web Page Problem
When you search for "FDA drug approvals this month," Google returns 10 blue links in 300 milliseconds. Impressive engineering—but completely useless if you're building a database of every approval that happened.
Traditional search engines solve a fundamentally different problem. They optimize for relevance ranking (which 10 results are best) assuming human consumption. CatchAll optimizes for coverage (finding all relevant events) assuming downstream processing.
This is the architectural bet: process 50,000 web pages in 15 minutes to find 200 validated events with structured data. That 15-minute duration isn't a performance limitation we're trying to overcome—it's an intentional choice that prioritizes completeness over latency.
This is how we built it, what worked, and what was harder than we expected.
Meta-Prompting Architecture
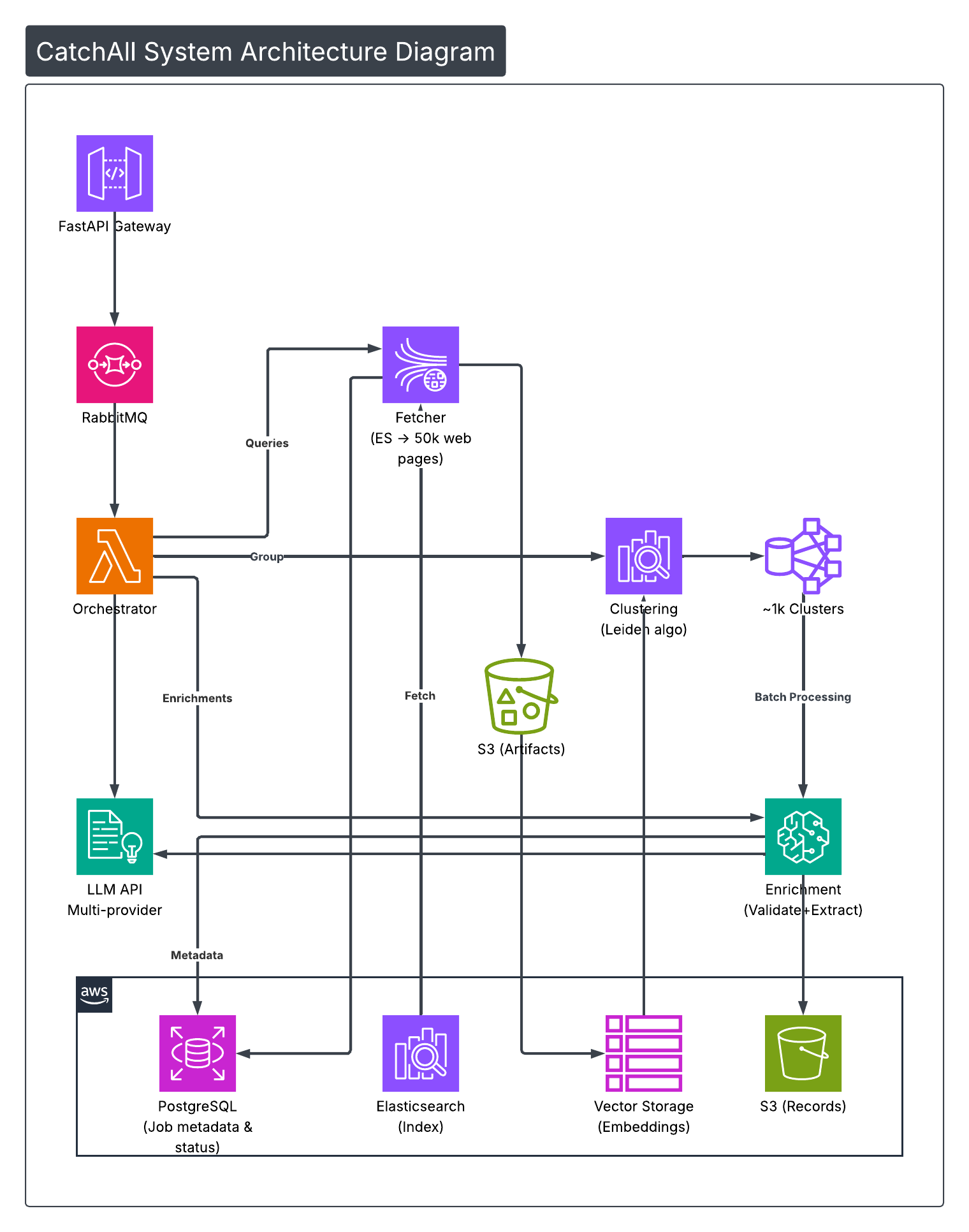
Here's CatchAll's key architectural insight: instead of hardcoding validation rules or extraction schemas, we use LLMs to generate the prompts that other LLMs will execute later. This meta-prompting approach is how we handle infinite query types without hardcoding anything.
Stage 1: Analysis — LLMs Writing Prompts for LLMs
The analysis stage makes multiple sequential LLM calls:
Call 1: Query Scoping extracts metadata—date ranges ("recently" → absolute dates), geographic scope, language requirements, and more. We also detect injections and security issues, such as prompt hijacking attempts. The system logs, detects, and aborts these efforts immediately. detects it, logs the attempt, and fails the job immediately.
Call 2: Validator & Extractor Generation is where meta-prompting happens. The LLM doesn't validate or extract anything yet. It generates complete prompts that other LLMs will execute later. The validator prompt defines boolean criteria such as "is the event about a labor strike", "is the event in the defined timeframe", etc. The extractor prompt defines JSON schemas with field types. These are prompts-as-data—stored and executed in later stages.
Call 3: Search Query Generation produces 5-20 Elasticsearch queries optimized for recall, not precision. Multiple query strategies (primary sweep, synonym expansion, proximity patterns) ensure comprehensive coverage. The system explicitly aims to retrieve 10,000 web pages with 500 relevant ones rather than 100 web pages with 90 relevant ones.
Stages 2-5: Execution Pipeline
Fetching (5 min) executes generated queries against NewsCatcher's index of two billion web pages. Multiple queries return overlapping results by design—better to fetch duplicates than miss events. Simple deduplication produces 40k-50k unique web pages with embeddings.
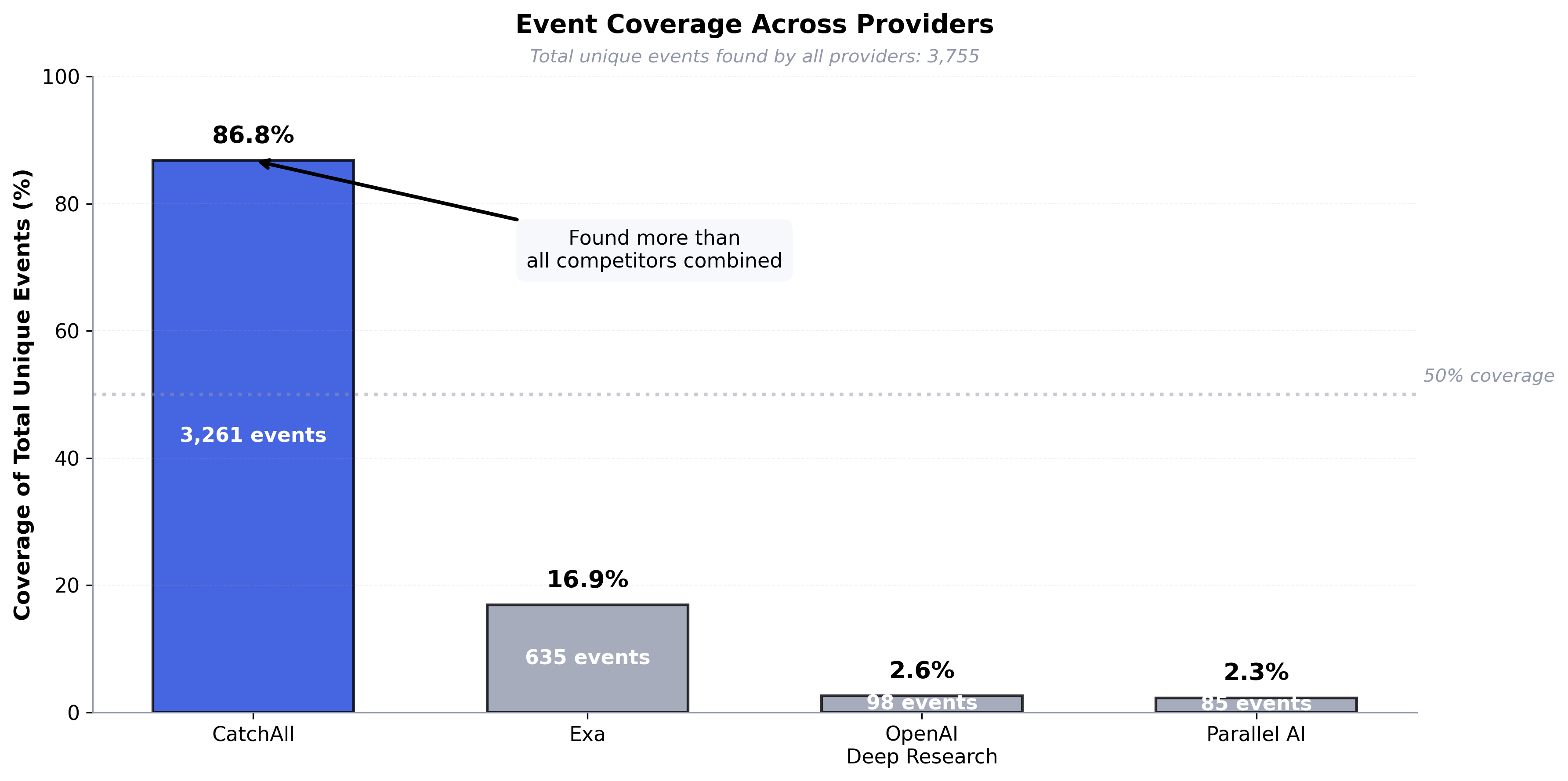
Clustering (3 min) uses Leiden community detection to group 50k web pages into ~1,200 event clusters. Pure graph-based operations on embedding similarities—no LLM calls, fast and deterministic. After extensive testing against DBSCAN, HDBSCAN, and BERTopic, Leiden delivered the results that enabled CatchAll to achieve 77.5% observable recall in production—finding 3 out of 4 relevant events while competitors find 1 out of 4.
Validation & Extraction (5 min) executes the meta-prompts from Analysis through batch processing: while Batch 1 completes extraction, Batch 2 undergoes validation, and Batch 3 begins processing. This overlapping execution enables early result access during the enriching stage—you can retrieve validated records from completed batches while remaining clusters continue processing.
For each cluster in a batch, the system takes up to 5 web pages and applies the validator prompt → boolean results. The rejection rate is deliberately high (around 80% of clusters) by design to achieve better precision. On validated clusters, the extractor prompt produces structured event records in JSON.
Event Deduplication handles cases where multiple validated clusters represent the same event. Three-step process: Leiden clustering on extracted records, LLM validation using a proprietary event identifier framework that matches records by issuer, instrument type, and timeframe, then LLM merging of duplicates.
Performance at Scale: What 15 Minutes Buys You
Time Breakdown
Representative job processing 50,000 web pages:
Throughput Characteristics
Processing rate: ~50 web pages/second average, >100 web pages/second peak during fetching.
Intentional bottleneck: We deliberately bottleneck on validation quality rather than fetching speed. The system could retrieve faster, but that would just move the constraint downstream. Current balance optimizes for accurate results over raw throughput.
Scaling Characteristics
Horizontal scaling (concurrent jobs): Perfect parallelization. 10 jobs = same 15 minutes as 1 job. Just add workers.
Vertical scaling (web pages per job): Non-linear due to clustering memory. Graph operations scale O(n²):
- 10k web pages: ~8 minutes
- 50k web pages: ~15 minutes
- 100k web pages: ~35 minutes (extrapolated—not recommended)
Long Tail Problem
What we observed: Most queries completed in 12-15 minutes, but some took >60 minutes. These weren't random—queries generating massive result sets overwhelmed clustering.
How we fixed it: Pre-retrieval optimization. The system detects queries returning excessive results and adds theme exclusions or narrows scope before clustering. This brought 95th percentile from >60 minutes to ~25 minutes without affecting median performance.
Critical limitation: Extremely broad queries now get automatically scoped. "Find all news from December 2024" might narrow to "Find all news about [specific themes] from December 2024." This prevents timeouts but means some queries won't return literally everything.
Production Lessons
Building CatchAll taught us more about production AI systems than any amount of theory could. Here's what actually mattered.
What Worked
Message-driven architecture was the right choice. Early on, we committed to RabbitMQ-based microservices despite added complexity. When validation started taking longer than expected, we just scaled the enrichment service. When clustering needed more memory, we scaled it vertically without touching other services. Jobs can fail halfway through and resume from the last completed stage—users never see partial failures.
Task-specific LLM optimization over one-size-fits-all. Initial versions tried everything in a single LLM call. Results were inconsistent—sometimes great, sometimes terrible. We learned that specialization matters at two levels. First, splitting into three sequential calls with different objectives (scoping, validation/extraction generation, query generation) produced dramatically better results—separate prompts mean separate optimization loops. Second, no single LLM provider excels at every task. In production, we use a mix of LLM major providers, each selected for specific strengths: one for boolean validation logic, another for structured extraction, another for semantic deduplication. This dual specialization—by task phase and by provider—delivered compound improvements that single-model approaches couldn't match.
Cluster-level validation was key.Validating clusters with 5 web pages each is more efficient than validating individual web pages (processing time measured in minutes vs hours for serial validation). But efficiency isn't the only benefit—quality improves too. Validation with 5 web pages provides more context than validating single web pages. The LLM can cross-reference facts, catch inconsistencies, and make better relevance judgments.
Leiden clustering enabled production-quality recall. After extensive testing against DBSCAN, HDBSCAN, and BERTopic alternatives, Leiden consistently produced the clustering quality that enabled CatchAll to achieve 77.5% observable recall in production benchmarks—finding 3 out of 4 relevant events while maintaining structured extraction quality. In competitive evaluations, CatchAll achieved 60% better F1 scores and won 71% of query comparisons against alternatives that optimize for precision over recall.
What Was Hard
Balancing recall and precision is ongoing. The architectural bet is clear: optimize for recall (finding more relevant events) over precision (showing only perfect results). In competitive benchmarks, this approach achieved 3x the recall of alternatives. But for better precision, aggressive filtering is essential—the system rejects approximately 80% of clusters during validation. We chose comprehensive coverage with filtering over limited results, but it's a deliberate trade-off that suits specific use cases better than others.
Dynamic schemas create integration friction. Developers expect deal_value to always be called deal_value. But LLMs might generate transaction_amount, deal_size, or acquisition_value. All mean the same thing, but integration code must parse dynamically. We document this extensively and provide SDK patterns—but it's still a learning curve for teams expecting fixed schemas. Monitors help address this: since they reuse the same validators and extractors from a reference job, field names stay consistent across recurring runs, reducing integration complexity for ongoing data collection.
Keeping CatchAll affordable without compromising quality. We explored various optimization strategies to reduce costs while maintaining the recall advantage. The winning approach focused on pipeline efficiency: better preprocessing (embedding caching for repeated queries), improved validators that catch irrelevant clusters earlier (reducing unnecessary LLM calls in extraction), and optimized batch processing. These indirect optimizations preserved quality while reducing computational overhead.
The long tail is expensive. Handling the 95th percentile without breaking the average case—that's where the real work is. Some queries generated result sets far exceeding typical volumes, creating outliers that dominated latency budgets. Pre-retrieval optimization—detecting these cases and adding theme exclusions or narrowing scope before clustering—brought outlier completion times down significantly without affecting typical job performance.
Conclusion: Rethinking Search for the AI Era
The main insight from building CatchAll is clear: AI systems require fundamentally different infrastructure than the systems built for human users.
CatchAll processes 50,000 web pages in 15 minutes. This is not because we couldn't make it faster, but because comprehensive coverage needs a fundamentally different architecture than traditional search. When the goal is to find every relevant event—not just the best match—you need systems built for recall and validation at scale, plus structured extraction.
All our architectural choices—message-driven pipeline, meta-prompting for validation, graph-based clustering, aggressive filtering—are based on a core insight: AI systems don't need better ranking algorithms—they need complete, structured data. This insight is validated by our production results: 77.5% observable recall, finding 3 out of 4 relevant events. Our competitors find 1 out of 4, and we achieve 60% better F1 scores across diverse query types.
Traditional search was designed for humans to read results. AI systems need something different. CatchAll represents an early attempt at building that different thing—not a search engine with an AI wrapper, but a coverage-first pipeline that uses AI at key decision points.
We've shared these architectural insights because this is a category worth building, not just a product worth selling. As AI systems grow more sophisticated, they need better data infrastructure, not just better models. The search problem isn't solved—it's just being solved for a new audience.
Try It Yourself
Get started: platform.newscatcherapi.com
Documentation: newscatcherapi.com/docs/v3/catch-all
Benchmark Details: How We Evaluated CatchAll Against Competitors
Questions? support@newscatcherapi.com