





















Understand the need for news syndication and the various ways you can aggregate news data yourself. Learn to build your own crypto news aggregator.
News publishers have been muddling through a long-term digital transformation for quite some time. But the shock waves of the pandemics have put these plans into overdrive. According to recent reports from the World association of News Publishers, editorial has overtaken print production and distribution for the first time to become the largest expense in news organizations. This signals a tipping point in the contested dominance of physical vs digital news.
And with this transition, it has become easier for people to create their own news publications without worrying about the upfront cost of printing thousands of newspapers. This has good and bad consequences. On one hand, this makes it easier for investigative and independent journalists to get their word out there. On the other hand, the increased number of news publications makes it harder for the audience to keep up with the news as the sources are fragmented. Visiting many separate websites frequently to find out if the site has new information is tiring.
This is where news aggregators shine!
What Are News Aggregators?
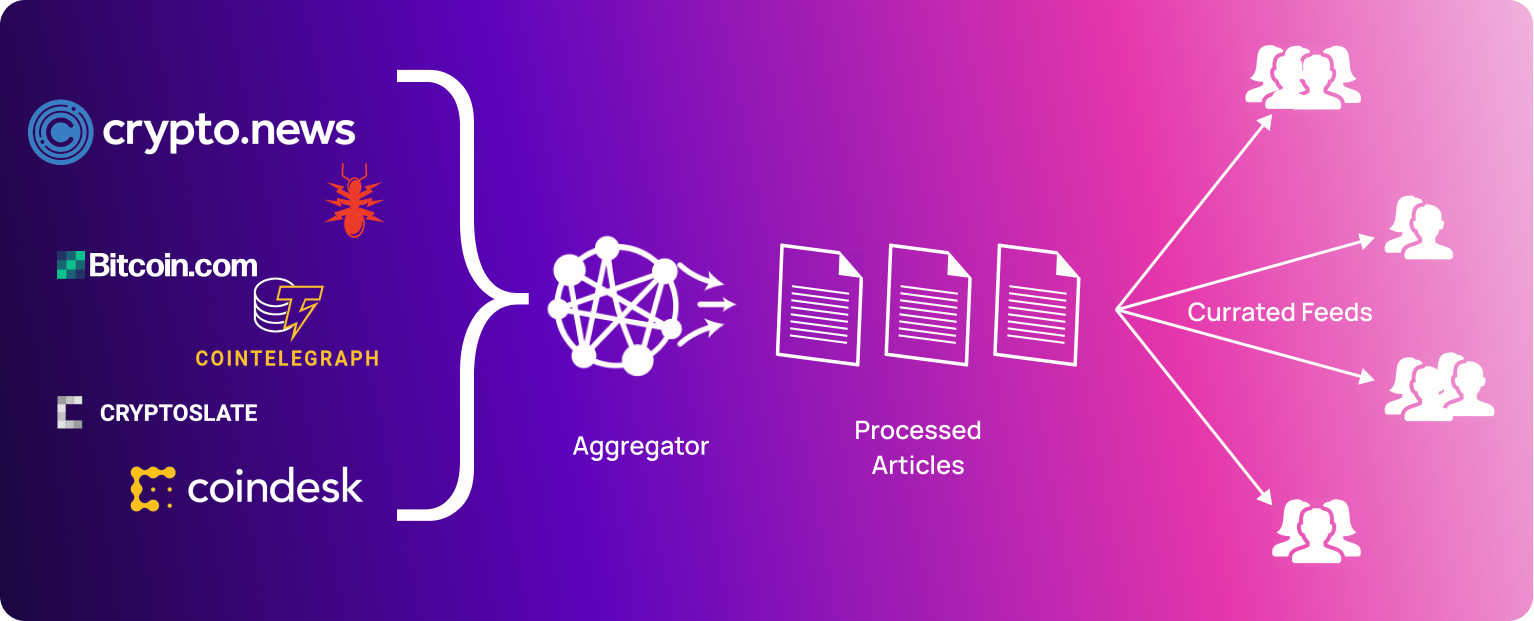
News Aggregators are websites or applications that collect news stories as they are published on the web and organize the information in a specific manner. It is based on the concept of content syndication, where content created by a group of content publishers is distributed through a different organization.
This syndication of news content enables the audience to get all their news without checking a bunch of different websites. It also opens up the possibility of curation. This can be accomplished in several ways. Some aggregators have their own recommendation algorithms and some are curated by people to whom certain types of information are of particular import. There are also some aggregators that allow the end-user to manually configure what publications and what kind of stories they want to read.
Top News Aggregators
Here are some news aggregators you may have used or heard of:
Sources Of News Data

There are many ways of going about aggregating content from news publications. And there is no one, strict right answer for all use cases. Let’s take a look at the different ways you can get content for your news aggregator.
RSS Feeds
RSS, (RDF Site Summary or Really Simple Syndication), is a web feed format that enables humans and computers to access updates to websites in a standardized, easy-to-understand way. In simple words, articles are gathered from the website to create a feed. The subscriber gets a brief description with a link to the original version. Most news websites have an RSS feed, but a few don’t (yes, I am looking at you Reuters).
Web Scraping
Another method to get news data is to create custom website scrapers for each news publication. These scrapers are generally used in conjunction with RSS feeds or sitemaps as they need the URLs of the articles to get the data. Scapers enable you to get a lot more data compared to RSS feeds but they are time-consuming to create and set up.
News Publisher's APIs
Some of the big news publishers such as the New York Times, The Guardian, and Bloomberg have their own news APIs. These are generally paid services. But they might agree to give you the data for free if your application is non-profit and/or educational in nature.
Build A Crypto News Aggregator
Let's pick a niche and build a news aggregator to understand some of the challenges you would face while building one. Cryptocurrencies and web3 have been growing in popularity in the past few years, and as a result, a lot of crypto-specific news publications have popped up. So, why don’t we aggregate these publications to create a single source of information for all things crypto?
Crypto News Aggregator With RSS Feeds
To build a news aggregator with RSS, the first thing you’ll need is to get the URLs for the RSS feeds of the sources you want to aggregate. For this tutorial you’ll be working with the following ten sources:

And here are the links to their RSS feeds:
In order to extract information from these RSS feeds you’ll have to fetch them and then parse the XML syntax. And since working with RSS feeds is a common thing, there are nifty Python modules like feedparser.
Here’s what it returns for the coindesk.com RSS feed:
The individual items or articles are stored as a list of dictionaries in the 'entries' key.
Take a look at what the 'entries' syntax look like for the different sources:
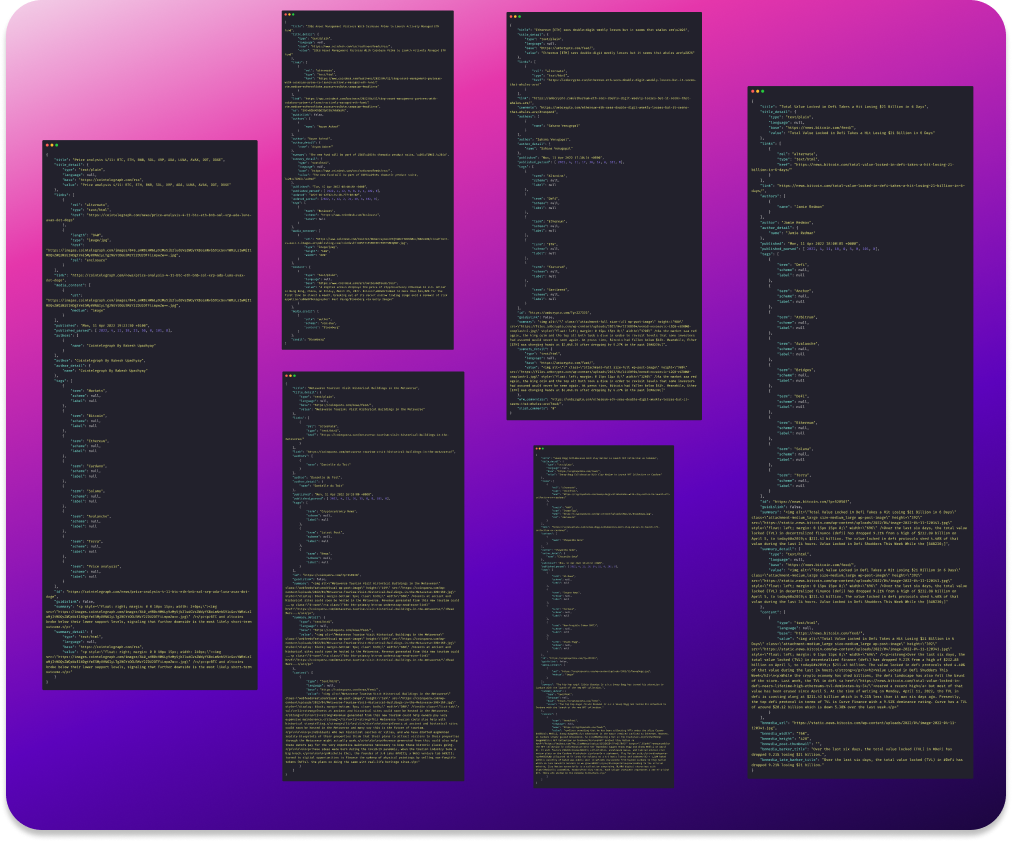
Hmm, the article entries have different syntax for different sources. Some of the attributes like 'title', 'link', and 'publish date' have the same format but things like 'summary' and 'image' have different formats. Sometimes the data is inside some HTML tags, and sometimes it is missing altogether. For instance, there is no image attribute in the case of NullTx and CryptoSlate 😕
To normalize this data you have to go through one article entry for each of the RSS feeds and figure out a way to extract relevant data points. Don’t worry a lot of them do share syntax.
Here’s what I came up with for the ten crypto news sources:
It’s not the most elegant solution, but it gets the job done. Here’s the gist of it:
When the value of a key is a string such as ‘summary’, it can be accessed using the value string as the index.
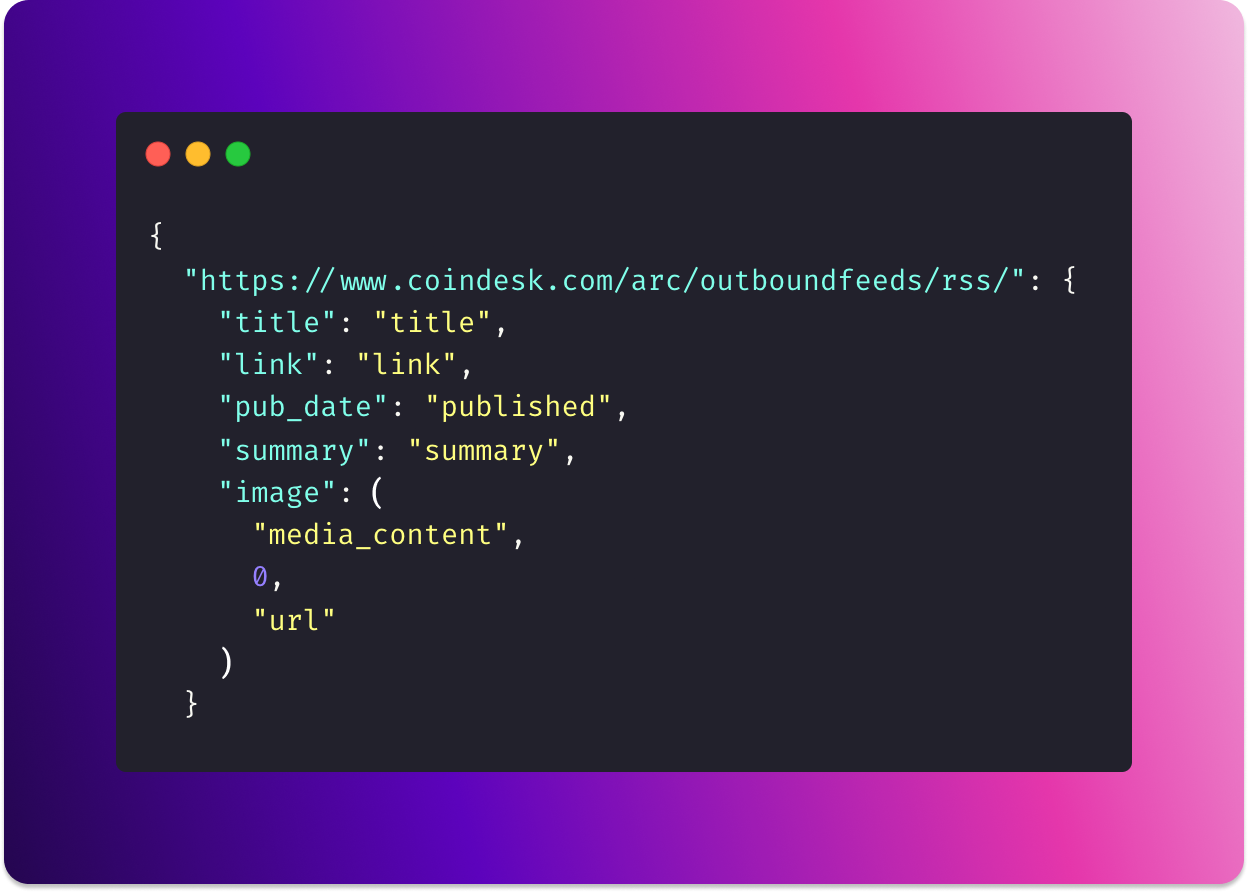
If the value is a tuple like ("media_content", 0, "url"), the values need to be chain-indexed to access the relevant information.
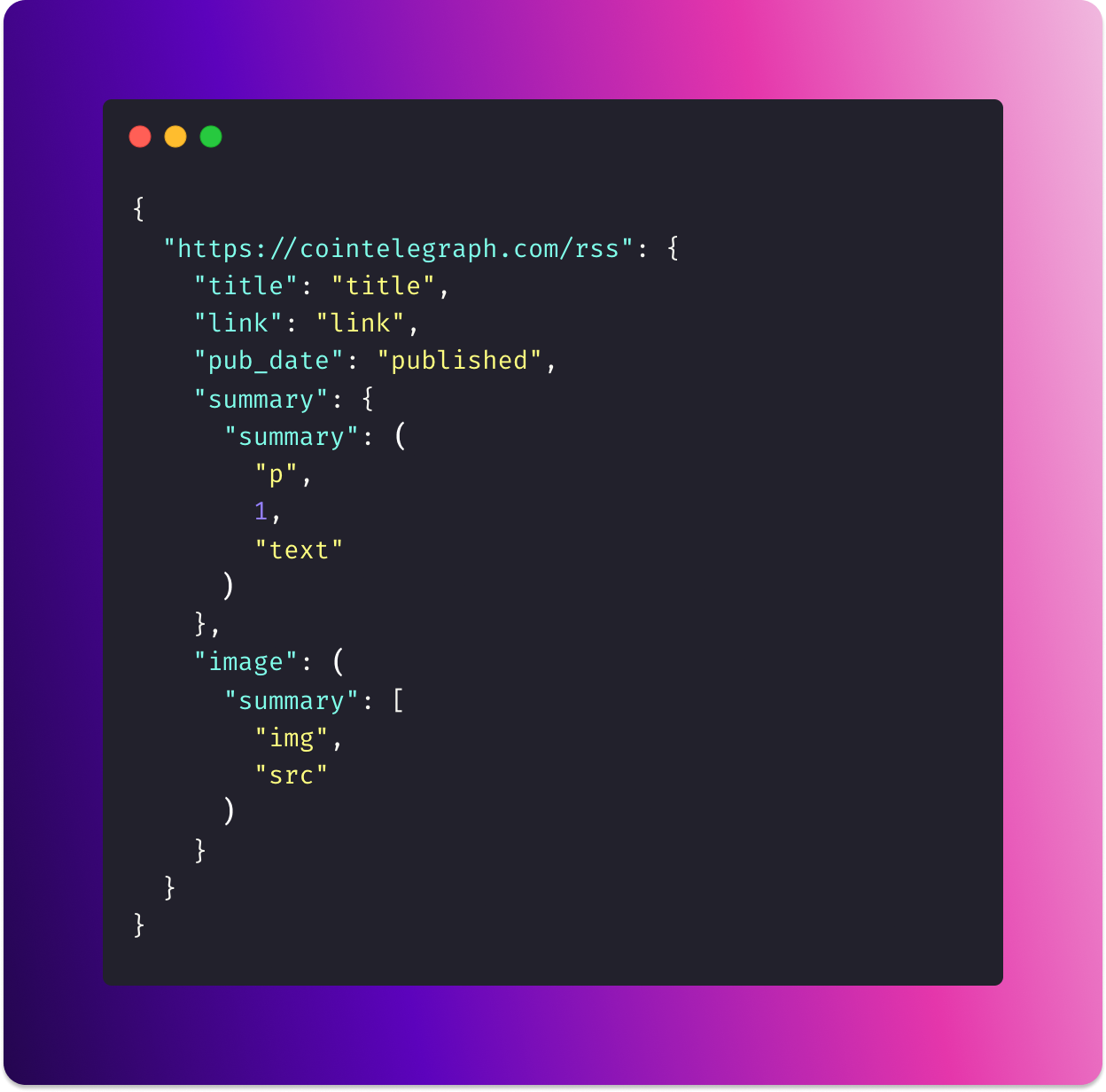
And finally, if the value is a dictionary, the nested key attribute from the feedparser output needs to be parsed as HTML by BeautifulSoup. And then the nested tuple values can be used to extract relevant information.
Here’s what you would get after combing all of this together in a loop:
Testing it to print one article for each source, you get:
And you're done!
You can use the following streamlit code snippet to create a quick, decent looking web application for this aggregator:
Now, this is quite cool and it could be made into a respectable personal project. But exclusively using RSS feeds for news aggregation has some limitations.
Drawbacks Of Using Just RSS Feeds
Firstly, it’s tiring to add new sources. You need to fetch the RSS feed, see the syntax of the individual entries and figure out how to extract the information you want. This is feasible for 10-20 sources, but as that number moves up things get tiring.
Second, you’re not guaranteed to get all the attributes you want. Remember, you couldn’t get the images for NullTx and CryptoSlate.
And third, the information is very limited. The idea behind RSS feeds is not to enable you to access everything in one place, but to allow you to glance through recent updates. So if you want to add more value to your aggregator using Natural Language Processing (NLP), you’ll need to get the full article text. To overcome this, you can create individual scrapers for each of the websites but that would require tremendous time and effort.
There’s a hack for working around this issue. Don’t aggregate the data yourself 😬 Either scrape an existing news aggregator such as Google News or use a general-purpose news API like NewsCatcher.
Crypto News Aggregator With NewsCatcher News API
To get the same data you extracted using RSS feeds, all you need is a list of source URLs and a free API key.
Install the newscatcherapi Python SDK, get an API key for free, and that’s it! You can just pass in the list of sources as a parameter and you’ll get all the data you need:
Let’s create a loop to get the relevant article properties:
That was so much easier, wasn’t it?
Not to mention the fact that you can search through the articles using our API, and add new sources easily. You can even get older articles if you wanted to.
Here's the news aggregation app you can make using the news articles you learned to fetch:
Conclusion
In this article, you learned about news aggregation and built your news aggregator. You can now further enrich this aggregator by using NLP to extract useful information from the articles. Or by incorporating live price feeds for the crypto assets of your choice. Another way of improving this news aggregator is incorporating relevant news articles from traditional finance publications like Bloomberg, Forbes, MSNBC, etc.
Here are some ideas to help you get started with the development of the NLP features:
- Perform sentiment analysis with a transformer model trained on financial texts
- Detect events and entities using named entity recognition (NER) or spaCy’s Matcher class
- Label crypto assets, protocol, and token symbols using spaCy’s PhraseMatcher







































