





















Annotation is the part where most projects stall, and it can make or break your models. Here are some tools and tips to help you with text annotation needs.
Even with all the recent advances in machine learning and artificial intelligence, we can’t escape the irony of the information age. In order for humans to rely on machines, machines need humans first to teach them. So if you're doing any type of supervised learning in your natural language processing pipeline, and you most likely are, data annotation has played a role in your work. Maybe you were lucky enough to have a large pre-annotated text corpus. And you didn't need to do all the text annotation for training yourself. But if you want to know how well it's doing in production, you'll have to annotate text at some point.
What Is Text Annotation?
Text annotation is simply reading natural language data and adding some additional information about it, in a machine-readable format. This additional information can be used to train machine learning models and to evaluate how well they perform.
Let’s say you have this piece of text in your corpus: “I am going to order some brownies for tomorrow”
You might want to identify that brownies are a food item and/or that tomorrow is the delivery time. Then use that piece of information to ensure that you have some brownies for them and that you can deliver them tomorrow.

Or maybe your task is on a larger scale. So you might want to annotate that the whole sentence has the intent of placing an order.
Tips To Make Your Text Annotation Process Better

The first thing you can do to make the life of your annotators and developers simple is to keep the labels simple and descriptive. food_item and time_of_delivery are good, straightforward labels that describe what you’re annotating. But labels like intent_1, intent_1_ver2, and unnecessary acronyms make it harder to quickly apply and check labels.
Besides that, it’s unlikely that one person is going to be annotating everything on their own. Usually, there is a team of people that need to agree on what the labels mean. I recommend that you define your labels in a central shared location and keep this information up to date. So if a new label is added, or if the meaning of a label changes, everyone has easy access to the updates.
Checking The Quality Of Your Text Annotations
One often overlooked thing is checking the quality of your annotations. Well, how does one even do that? You could go through all of the text again, but that’s inefficient.
One handy technique is to use a flag to denote confusion or uncertainty about an annotation. This enables annotators that are unsure about an annotation to flag it, allowing it to be double-checked later.
Another helpful method is to have some annotators look at the same data, and compare their annotations. You could use a measure of inter-rater reliability like Cohen's kappa, Scott's Pi, or Fleiss's kappa for this. Or you could create a confusion matrix.
In the example above, annotator 1's labels are in the columns and annotator 2's labels are in the rows. You can see that they both agree on all the things labeled order_time, and they mostly agree on the food_item. But there seems to be a lot of confusion about where the label food_order should be applied.
This might be a sign that the label needs more clarification about its meaning, or that it needs to be slit into separate labels. Or maybe it should be removed completely.
Top Text Annotation Tools
brat (Browser-Based Rapid Annotation Tool)
brat is a free, browser-based online annotation tool for collaborative text annotation. It has a rich set of features such as integration with external resources including Wikipedia, support for automatic text annotation tools, and an integrated annotation comparison. The configurations for a project-specific labeling scheme is defined via .conf files, which are just plain text files.
brat is more suited to annotating expressions and relationships between them, as annotating longer text spans like paragraphs is really inconvenient (the pop-up menu becomes larger than the screen). It only accepts text files as input documents, and the text file is not presented in the original formatting in the UI. So it is not suitable for labeling structured documents like PDFs.
It comes with detailed install instructions and can be set up in a few lines of code.
To set up the standalone version, just clone the GitHub repository:
Navigate into the directory and run the installation script:
You’ll be prompted for information like username, password, and admin contact email. Once you have filled in that information, you can launch brat:
You will then be able to access brat from the address printed in the terminal.
doccano
doccano is an open-source, browser-based annotation tool solely for text files. It has a more modern, attractive UI, and all the configuration is done in the web UI. But doccano is less adaptable than brat. It does not have support for labeling relationships between words and nested classifications, however, most models and use cases don’t need these anyway.
You can write and save annotation guidelines in the app itself and use keyboard shortcuts to apply an annotation. It also creates a basic diagrammatic overview of the labeling stats. All this makes doccano more beginner, and in general user, friendly. It does support multiple users, but there are no extra features for collaborative annotation.
The setup process is also quite simple, just install doccano from PyPI:
After installation, run the following commands:
In another terminal, run the following command:
And go to http://127.0.0.1:8000/ in your browser.
LightTag
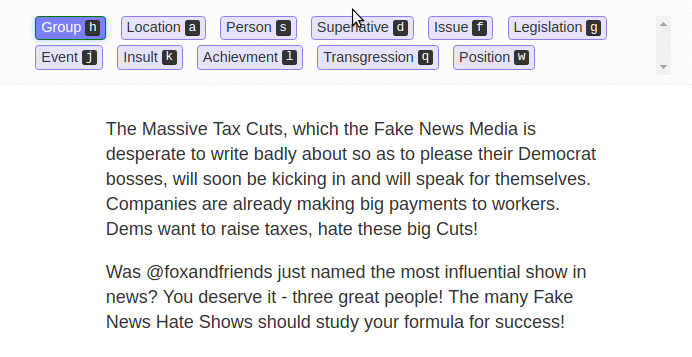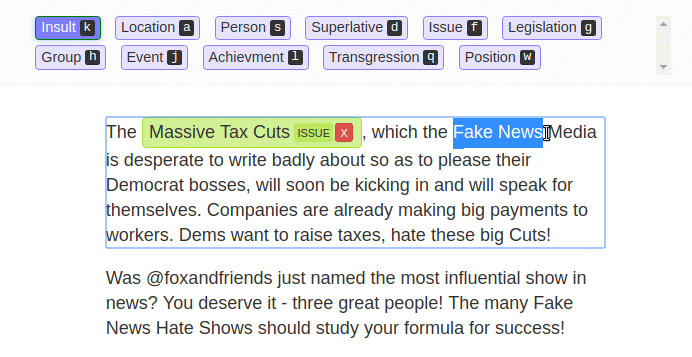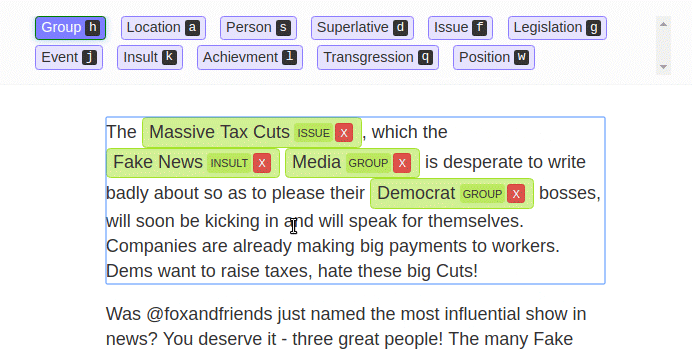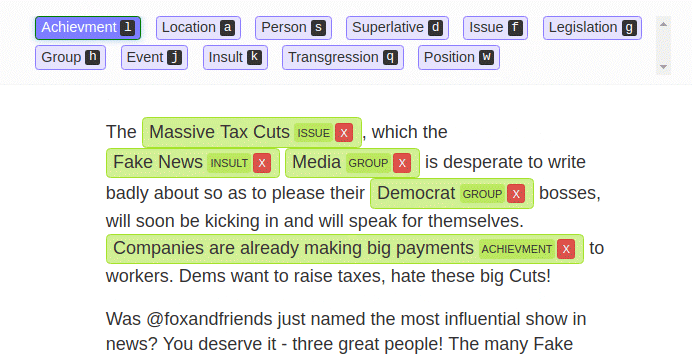
LightTag is another browser-based text labeling tool, but it isn’t entirely free. It has a free-for-all version with 5,000 annotations a month for its basic functionalities. You just need to create an account to start annotating.
The LightTag platform has its own AI model that learns from the previous labeling and makes annotation suggestions. For a fee, the platform also automates the work of managing a project. It assigns tasks to annotators, and ensures there is enough overlap and duplication to keep accuracy and consistency high.
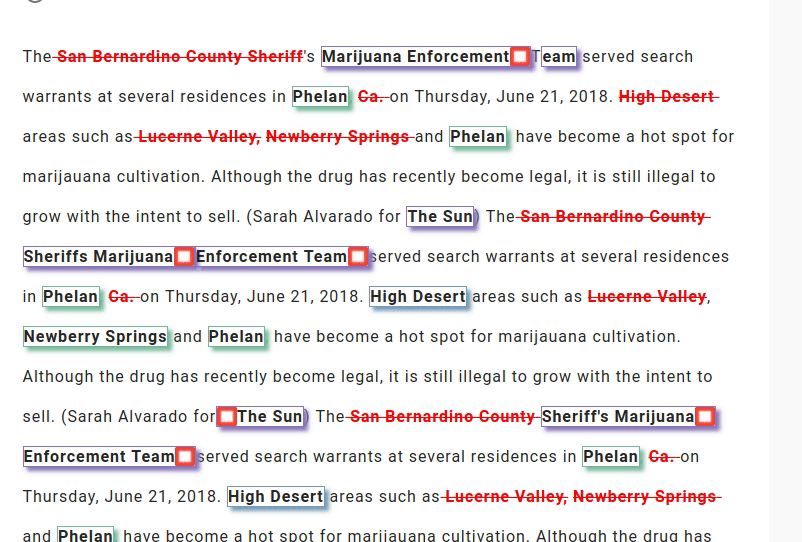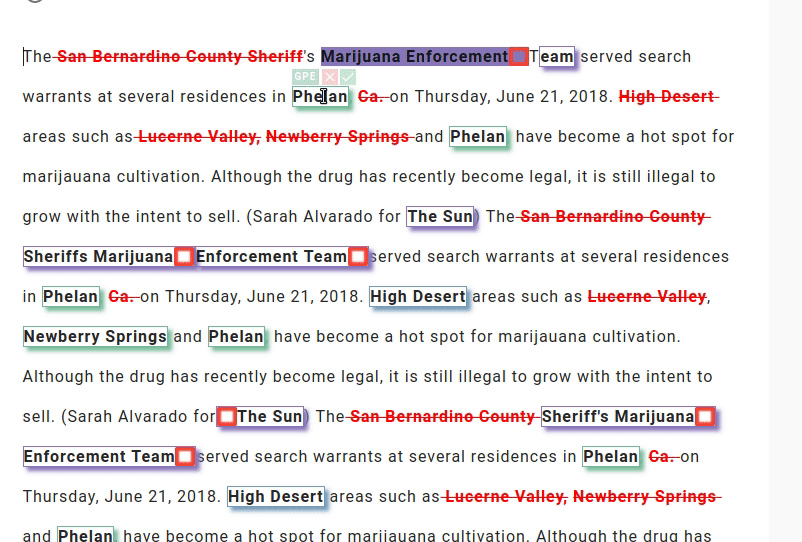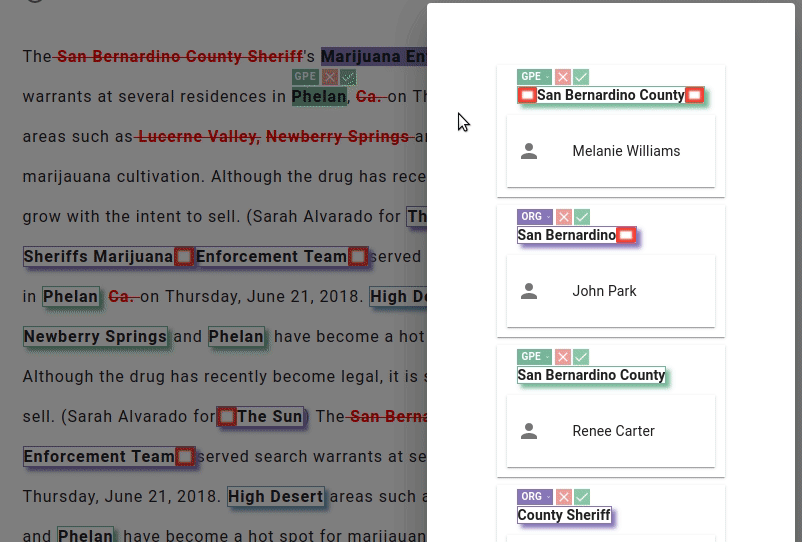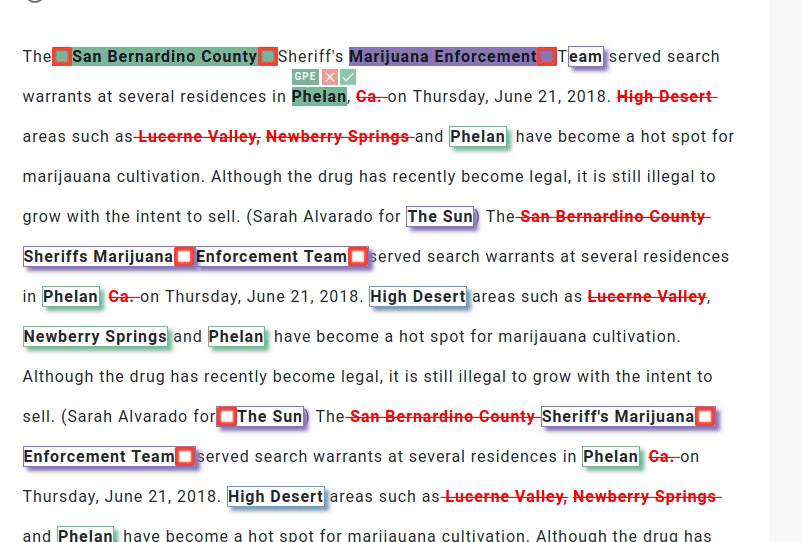
What really makes LightTag stand out, in my opinion, is its data quality control features. It automatically generates precision and recall reports of your annotators, and has a dedicated review page that enables you to visually review your teams' annotations. LightTag also detects conflicts and allows you to auto-accept by majority or unanimous vote.
You can also load your production model’s predictions into LightTag and review them to detect data drift and monitor your production performance. It was recently acquired by Primer.ai, so you get access to their NLP platform with the subscriptions as well.
TagEditor
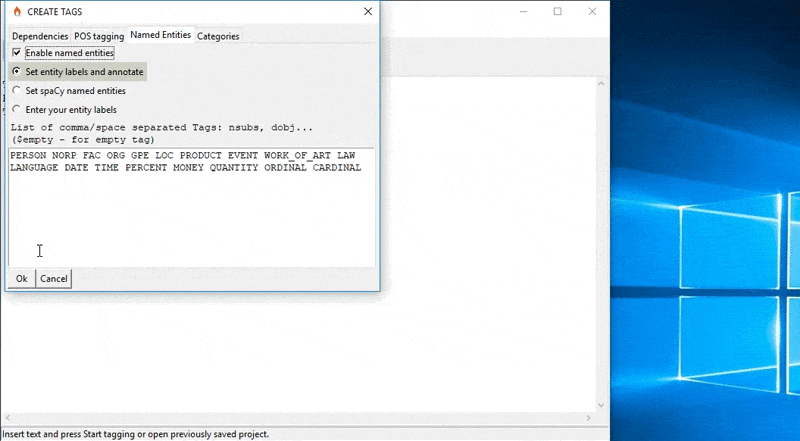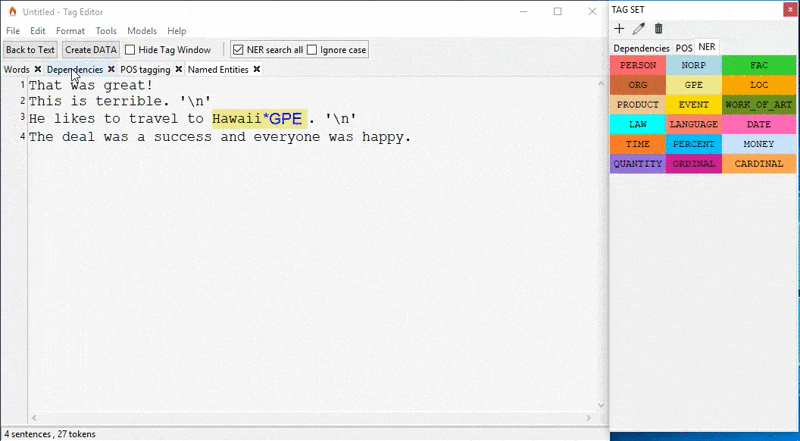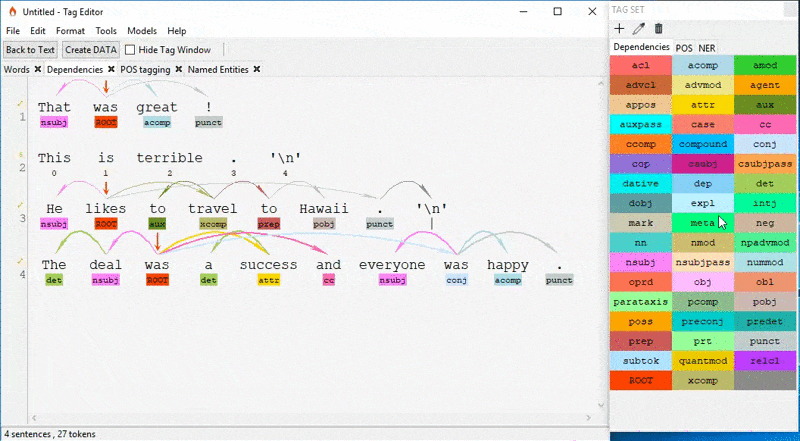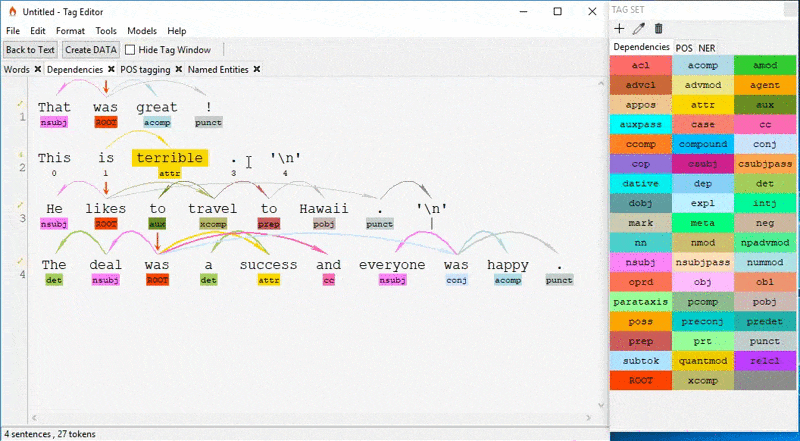
TagEditor is a standalone desktop application that enables you to quickly annotate text with the help of the spaCy library. It does not require any installations. You just need to download and extract the TagEditor.7z file from their GitHub repo, and run TagEditor.exe. Yes, it is limited to Windows 😬
With TagEditor you can annotate dependencies, parts of speech, named entities, text categories, and coreference resolution, create your customized annotated data or create a training dataset in .json or .spacy formats for training with spaCy library or PyTorch. If you're working with spaCy on Windows, TagEditor covers all bases.
tagtog
tagtog is a user-friendly web-based text annotation tool. Similar to LigthTag, you don’t need to install anything because it runs on the cloud. You just have to set up a new account and create a project. But if you need to run it in a private cloud environment, you can use their Docker image.
It provides free features to cover manual annotation, train your own model with Webhooks, and a bunch of pre-annotated public datasets. tagtog accelerates manual annotation by automatically recognizing and annotating words you've labeled once.
You can upload files in the supported format, such as .csv, .xml, .html, or simply insert plain text.
There is a subscription fee for the more advanced features like automatic annotation, native PDF annotations, and customer support. tagtog also enables you to import annotated data from your own trained models. You can then review it in the annotation editor and make the necessary modifications. Finally, download the reviewed documents using their API and re-train your model. Check out the official tutorials for complete examples.
Prodigy
The folks at Explosion.ai (the creators of spaCy) have their own annotation tool called Prodigy. It is a scriptable annotation tool that enables you to leverage transfer learning to train production-quality models with very few examples. The creators say that it's "so efficient that data scientists can do the annotation themselves." It does not have a free offering, but you can check out its live demo.
The active learning aspect of this annotation tool means that you only have to annotate examples the model doesn’t already know the answer to, considerably speeding up the annotation process. You can choose from .jsonl, .json, and .txt formats for exporting your files.
To start annotating, you need to get a license key, and install Prodigy from PyPI:
And if you work with JupyterLab, you can install the jupyterlab-prodigy extension.
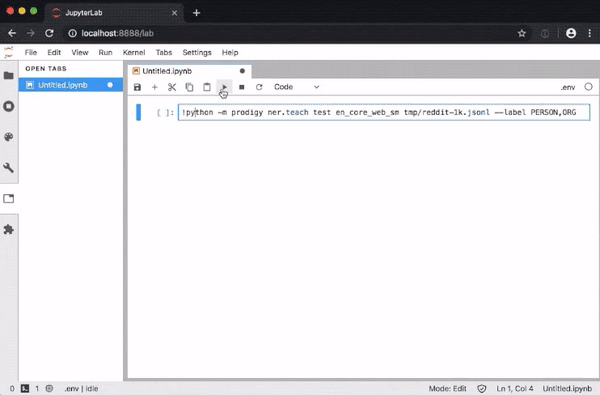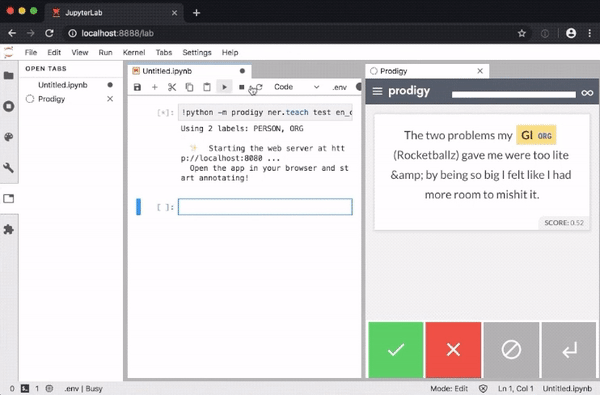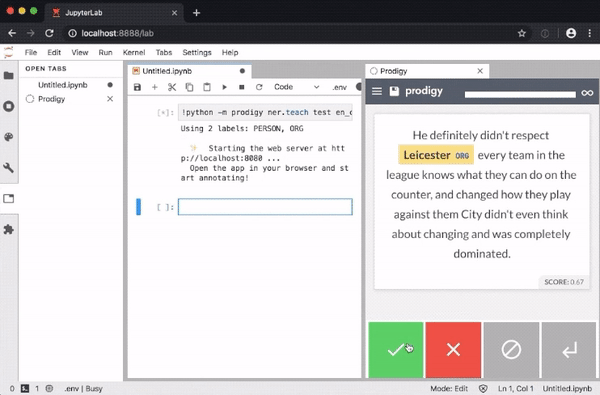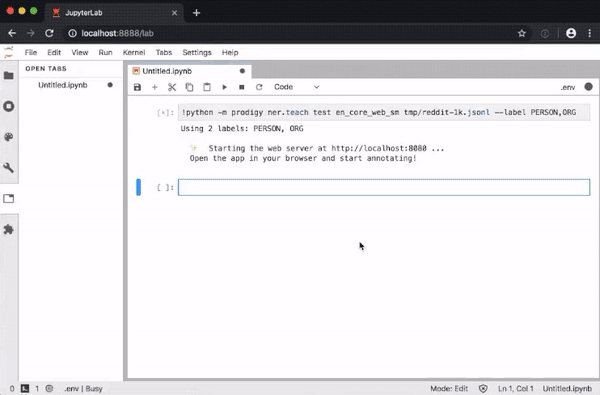
The extension enables you to execute recipe commands in notebook cells and opens the annotation UI in a JupyterLab tab, so you don’t need to leave your notebook to annotate data.
The Python library includes a range of pre-built workflows and command-line commands for various tasks, and well-documented components for implementing your own workflow scripts. Your scripts can specify how the data is loaded and saved, change which questions are asked in the annotation interface, and can even define custom HTML and Javascript to change the behavior of the front-end.
Prodigy is not limited to text, it enables you to annotate images, videos, and audio. It also has an easy-to-use randomized A/B testing feature that you can use to evaluate models for tasks like machine translation, image captioning, image generation, dialogue generation, etc.
Conclusion
If you can't spend any money, and your annotation task is something simple go with doccano. And if you need to label relationships go with TagEditor, but if you want more control and customization you can use brat.
On the paid tools front, Prodigy is the best option if you are willing to write some code to create data quality reports and manage annotation conflicts. While Prodigy does look like a pricey option upfront, it is worth noting that it is a one-time fee for a lifetime license with one year of updates. On the other hand, tagtog and LightTag are subscription services. But if you want a more ready out-of-the-box solution, you can go with tagtog or LightTag.





































