





















Learn what is named entity recognition, how it works, and how it can be used. Use spaCy to train your own custom NER model.
In this tutorial, we'll:
- Learn about named entity recognition(NER), how it works, and its applications
- Use spaCy's pre-trained NER transformer model
- Train a custom NER model with spaCy that extracts medical entities from journal texts.
What Is Named Entity Recognition?
Named Entity Recognition is one of the most pivotal data processing tasks in the field of Natural Language Processing(NLP). It aims to locate and categorize key information, i.e., entities, in text data. These ‘entities’ can be any word or any sequence of words(usually proper nouns) that consistently refer to the same thing. For instance, an entity detection system might detect the word “NewsCatcher” in text and classify it as an “Organization”.

At its core, all entity recognition systems have two steps:
- Detecting the entities in text
- Categorizing the entities into named classes
In the first step, the NER detects the location of the token or series of tokens that form an entity. Inside-outside-beginning chunking is a common method for finding the starting and ending indices of entities. The second step involves the creation of entity categories. These categories change depending on the use case, but here are some of the most common entities classes:
- Person
- Organization
- Location
- Time
- Measurements or Quantities
- String patterns like email addresses, phone numbers, or IP addresses
Although there are some rule-based entity recognition approaches, most modern named entity recognition systems make use of a machine learning/deep learning model. Due to its human origin, there is a lot of inherent ambiguity in text data. For instance, the word ‘Sydney’ can refer to both, a location and a person’s name.

There is no sure-fire way of dealing with such ambiguities but as a general rule of thumb, the more relevant training data is to the task, the better the model performs. For example, later in the article, we’ll be training a custom NER model that extracts medical information from clinical texts. Now, if we try to use this model to extract the same medical information from other types of text, say blog posts or news articles, it will do a lot worse.
Application Of Named Entity Recognition
NER is useful in any application in which a high-level understanding of a large quantity of text is needed. A good NER enables the computer to understand the subject or theme of text at a glance, and quickly group documents based on their relevance.
Information Extraction And Summarization
There is an enormous amount of text data being produced every day, but most of the text in documents is not necessarily useful. For example, insurance policy documents are extremely lengthy and have a lot of information. But insurance inspectors only need a specific set of information like name, contact details, age, etc. Being able to quickly extract and summarize this information saves a lot of time.
Optimizing Search Engines
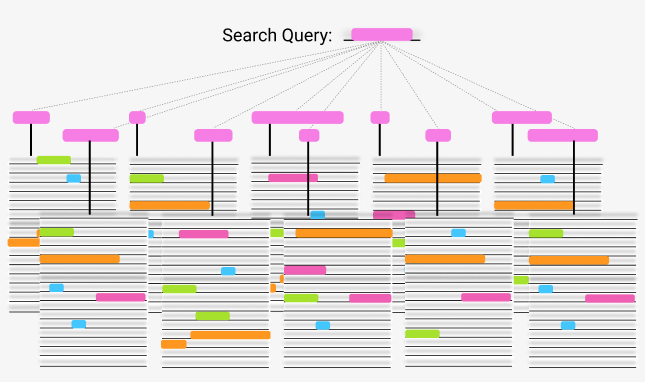
Let’s say were are creating an internal search engine algorithm for a news publisher that has millions of articles. If we create a simple substring look-up algorithm, it will end up going through all the words in the millions of articles. This will be rather slow. If we implement a NER, use it to extract relevant entities from the articles, and store them, we can optimize the search process. as the search query will only need to be matched on the list of relevant entities, the search execution will take less time.
Machine Translation
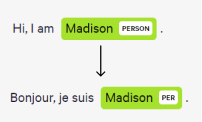
NER is also useful in translation applications as certain named entities like Person and Location don’t need to be translated, while others do.
Content Classification
News and publishing houses generate large amounts of online content on a daily basis and categorizing them correctly is very important to get the most use of each article. Named Entity Recognition can automatically scan entire articles and reveal which are the major people, organizations, and places discussed in them. Knowing the relevant tags for each article helps in automatically categorizing the articles in defined hierarchies and enables better content discovery.
Customer Support
There are a number of ways to make the process of customer feedback handling smooth using Named Entity Recognition. Let’s say we are handling the customer support department of an electronic store with multiple branches worldwide, you go through a number of mentions in your customers’ feedback. Like this for instance,
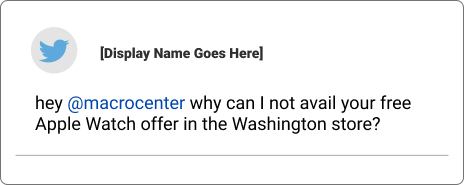
If we pass this tweet through the Named Entity Recognition API, it pulls out the entities Washington (location) and Apple Watch(Product). This information can be then used to categorize the complaint and assign it to the relevant department within the organization that should be handling this.
NER in spaCy
spaCy, regarded as the fastest NLP framework in Python, comes with optimized implementations for a lot of the common NLP tasks including NER. spaCy v3.0 even introduced the latest state-of-the-art transformer-based pipelines. By default, the spaCy pipeline loads the part-of-speech tagger, dependency parser, and NER.
So we can perform named entity recognition in a few lines of code:

Although this RoBERTa-based model achieves state-of-the-art performance on the CoNLL–2003 dataset it was trained on, it doesn’t perform as well on other kinds of text data. For instance, if we try to extract entities from medical journal text it won’t detect any relevant information.

To fix this we’ll need to train our own NER model, and the good thing is that spaCy makes that process very straightforward.
How To Train A Custom NER Model in Spacy
To train our custom named entity recognition model, we’ll need some relevant text data with the proper annotations. For the purpose of this tutorial, we’ll be using the medical entities dataset available on Kaggle.
Let’s install spacy, spacy-transformers, and start by taking a look at the dataset.

We only need the text string, the entity start and end indices, and the entity type.
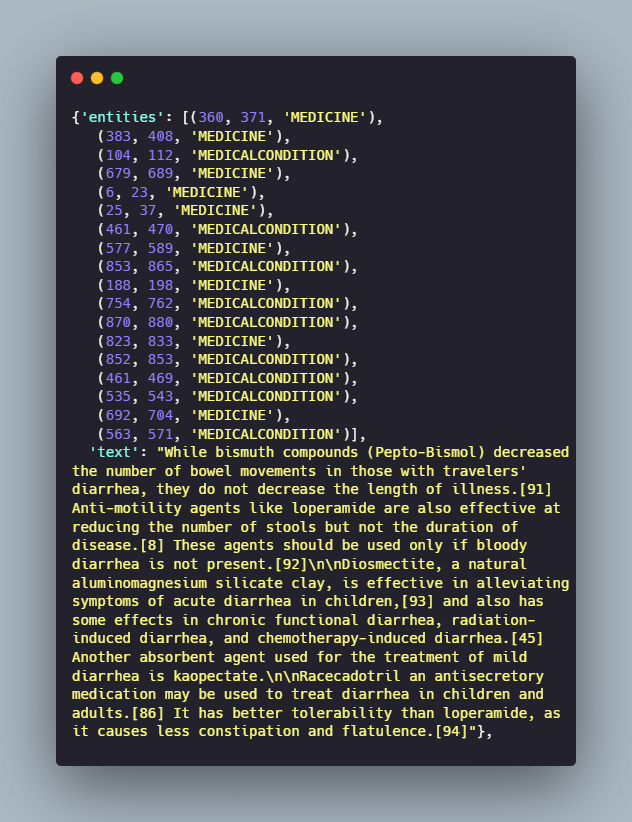
spaCy uses DocBin class for annotated data, so we’ll have to create the DocBin objects for our training examples. This DocBin class efficiently serializes the information from a collection of Doc objects. It is faster and produces smaller data sizes than pickle, and allows the user to deserialize without executing arbitrary Python code.
There are some entity span overlaps, i.e., the indices of some entities overlap. spaCy provides a utility method filter_spans to deal with this.
You can manually create a config file as per the use case or quickly create a base config on spaCy’s training quickstart page here.
We’ll be working with a base config file created using the quickstart page. This is an incomplete file with only our custom options, so we’ll have to fill in the rest with the default values.
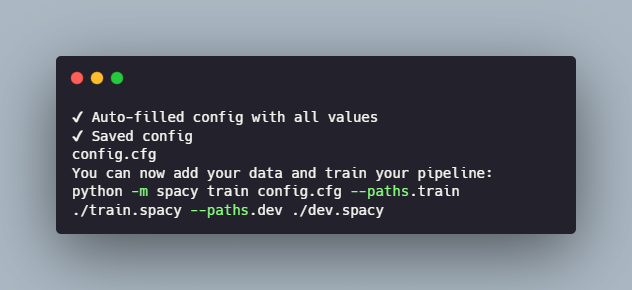
Now we have all that we need to train our model.
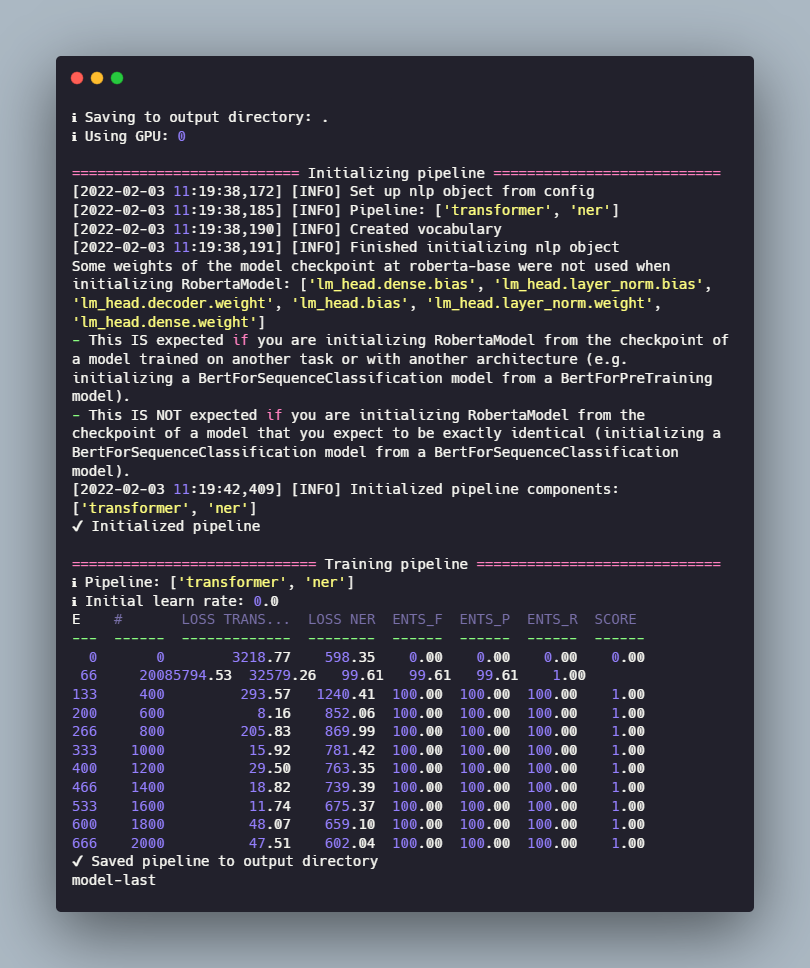
Let’s load the best-performing model and test it on a piece of text.

Even with the very limited amount of data the model achieves decent performance.
Conclusion
In this article, you learned how named entity recognition works, where it can be used, and then trained a custom NER model for extracting medical entities from journal text. You can use the same process to train a custom NER model for your applications, you'll just need some annotated data. In case you can't find any pre-existing datasets for your use case, you can use one of the following data annotation tools to create your own:







































