































Cost optimization replacing Cloud Run with Kubernetes Pods
Cut your Cloud Run bill in two in 30 minutes by replacing all heavy Cloud Run jobs with Docker containers running on the Kubernetes cluster.
In this post, I will tell the story of how we tried to migrate from AWS to Google Cloud as quickly as possible, became dependent on Cloud Run Service, received an average bill of $300/day just for Cloud Run.
Part I. Use Case
Part II. Architectural Transformation
Part III. Cost Optimization
Part IV. Guide On How To Migrate From Cloud Run To Kubernetes Cluster (To read only if you want detailed steps)
Why do we like Cloud Providers like AWS or GCP? We do not have to worry about maintenance and availability.
Services on GCP like Cloud Function or Cloud Run are so attractive at the beginning. You have your script, and you only need to add some configuration files or create an API. So you choose the service and upload the script, and voilà, it works better than expected. But then you receive a bill at the end of the month and are not so happy. You might even start to panic.
It happened to us last month. Here is a bit of context if you are interested. I am the CTO of NewsCatcher. At NewsCatcher, we provide instant access to all news articles published online. We are a news API.
We:
- crawl news websites,
- identify news article web pages,
- extract all relevant information (like title, published date, content, etc.),
- clean and deduplicate everything,
- finally, store it in our database.
After that, our clients can search through all of the news articles. Then, by choosing keywords and filtering by country, topic, rank, etc., they can find relevant news articles that help them gain a competitive advantage.
We're like Google for the news on the web, which you can access as a source of data.
Every day our servers process over 1,000,000 news articles from over 60,000 news websites. Our V1 is on AWS, and the primary data pipeline process is on Lambdas and SQS. It works fine. We pay a fair price for the number of invoked Lambdas. (See this article for more detail about our V1 architecture.)
It was time to move on, and we decided to build our V2 on GCP (mainly due to the $100k credits that we got becoming a member of the Station F incubator). However, we were in a hurry. We wanted to provide a functional V2 as soon as possible.
Because we were satisfied with our previous architecture, we tried to recreate it using Google Cloud Services. We replaced AWS Lambdas with Cloud Run and SQS with Pub/Sub. And of course, we increased the number of news articles extracted each day:
- V1 = 400k articles/day
- V2 = <1.5m articles/day
We were at least able to say why we charge more for V2. We also developed our algorithm to identify different ways to extract articles from various news sources.
Phew, everything worked fine, except for a tiny little thing — we have been paying 300 dollars a day for Cloud Run.
We had so many articles that 50 Cloud Run docker containers running 24/7 could not process them. We had hundreds of thousands of news articles that were delayed and waited in the queue.
We needed an alternative to Cloud Run, and we found one. Thanks to Universe, Google created Kubernetes. Therefore, we assumed that the Google Kubernetes Engine (GKE) is the best service providing Kubernetes functionality among other cloud providers.
Part I. Cloud Run Use Case
I will first describe the most expensive part of our data pipeline—article extraction. We have multiple techniques and tools to extract information from a news article.
We use Python, which is not the best language for web data extraction, but it works fine. It takes from 0.5 to 7 seconds to extract all relevant information from one article.
Every Cloud Run runs gunicorn as a WSGI server to communicate asynchronously with Flask Web App.
Here is what this process looks like:

- Receiving an item containing the URL of an article, website news source, and some additional info got into the first Pub/Sub
- Pub/Sub pushes a message to the dedicated Cloud Run Service and waits for it to be processed. If for a specified time Pub/Sub does not see a response from 200 to 206 from the Cloud Run, it considers a message unprocessed and returns it back into the pool
- When Cloud Run service is available for new messages, it processes them asynchronously and published to the next Pub/Sub
In the beginning, I thought, if I limited the number of Cloud Run docker containers to 50, we would only pay for 50 docker containers running in parallel. And if they will not be able to cover all of the traffic, the messages will be delayed and processed later. Only wins, right? Not really.

In the image above, you can see the number of requests received by our Cloud Run. In blue are all processed requests. In green is every other request that was delayed and resent every 5 minutes. Below is the number of unacknowledged/delayed messages:
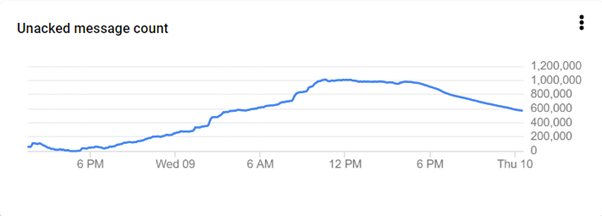
The downslope after 6:00 PM showed when I increased the number of Cloud Run docker containers from 50 to 200 to cover the pressure.
This highlights that my plan of
"50 containers will keep up with delayed messages later" did not work out.
I also want to point out that 200 could deal with it but would make us pay a hell of a lot more.
That is how I ended up thinking about Kubernetes (K8s in short) when looking for a solution. I just needed 200 less expensive docker containers.
If I am not mistaken, Cloud Run was introduced as an alternative to K8s with less configuration. So, using K8s instead of Cloud Run means returning to the roots. The more configuration, the less expensive service is. That's a rule of thumb.
Part II. Cloud Run to GKE
Below you will find the data pipeline modification that made the Kubernetes cluster work. If you are keen to know the exact steps in the script and additional configuration files, I will describe them in Part IV.
.jpeg)
as you can see, Step 2 is entirely different. Before, the Cloud Run docker was an API, and the Pub/Sub service could push messages into secured HTTPS addresses. A push action is a POST API call towards the Cloud Run Service. Now, Docker containers are deployed on K8s instead of waiting for API calls: they pull available messages and process them synchronously. Once one message is processed, it is sent to the next queue as before.
You might be asking yourself: "Why did he change from push to pull if docker containers could do the same job?" It's because I am not an expert in K8s. Pub/Sub only allows you to push messages into HTTPS secured addresses. By default, K8s pods are HTTP, and I did not have time to make them secured.
To sum things up, some architectural manipulation had to be done in order to replace Cloud Run Services with Kubernetes docker containers. You will see in Part IV that there are some minor changes to the script and configuration files.
Part III. Cloud Run Cost Optimization
We saved around 4500 dollars a month. Here is our bill for only Cloud Run:
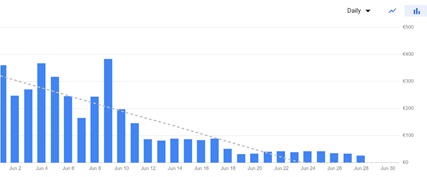
We were able to do cost optimization by replacing multiple Cloud Run jobs with Docker containers running on K8s. We used Cloud Run more as a proof of concept, but it is too expensive in Production.
Part IV. Guide On How To Migrate From Cloud Run To Kubernetes Cluster
If you are still reading this article, it probably means that you really want to know how you can do the same. I suggest looking at the complete Documentation of K8s when you have some free time for a better understanding. It will also find all code snippets in our GitHub Public Space. I want to highlight four major passages from the Cloud Run Service to K8s docker containers that you will have to deal with:
- Configure and create K8s Cluster on GKE
- Modify your existing scripts to fit K8s logic
- Upload code on Container Registry
- Deploy Docker containers on K8s
Configure and create K8s Cluster on GKE
1. We begin with creating a new K8s cluster on GKE

2. Choose “Standard” type. But, depending on your use case, “Autopilot” can be interesting as well
3. There is hell a lot of configurations. You can have a look on your own. I just want to pay attention to those worth configuring
4. In Cluster basics, carefully choose the cluster name
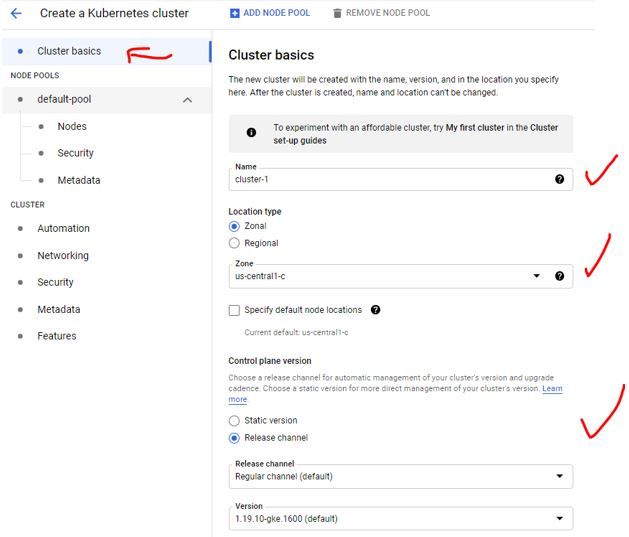
5. The control plane can be either a static version of it or updated whenever a new stable update is released
6. By default, there will be at least 3 nodes deployed. If you choose “zonal”, nodes will be deployed in the zone, but each on the different subzones (a,b,c, etc)
7. Now you configure your K8s nodes. Here, you must be very careful, because Nodes Configuration cannot be changed after creation. You will be able to increase and decrease the number of nodes, but their CPU and Memory by node will remain unchangeable. We use N2D Series which reveals to be very efficient

Those were the most important configurations. Have a look at all others as well. It will take some time to be launched.
Modify your existing scripts to fit K8s logic
as I mentioned previously, Cloud Run docker was an API service. It consists of main key files:
- main.py => Main script
- requirements.txt => Required packages
- Dockerfile => Docker file instruction
- key.json => Service account key to make script access other GCP services
In addition, my code is deployed on Production using Cloud Build connected to a GitHub account. Every time there is a new Pull Request merged with a Master Branch, the function in question will be redeployed. So, the fifth file would be cloudbuild.yaml with instructions, but of course, those extractions can be launched manually.
Let's have a look at Dockerfile and main.py used for Cloud Run.
Dockerfile
main.py
Here, I am sharing with you the core logic. I have an API service, which responds to the POST calls that contain some information about a news article. The service is running on gunicorn server communicating with Flask App. Once it receives a POST call, the function extract_article is triggered and makes its magic until it sends an extracted message to the next Pub/Sub.
Now, let's compare the new version of the Dockerfile and main.py created for running on K8s.
Dockerfile
main.py
Instead of having an API Service on Flask, Docker serves just to run the main.py script. And that's it.
In terms of python script, it pulls messages whenever there are enough in the Pub/Sub poll. It is an infinite loop. The containers are also all independent. If one falls, the other will continue to work. And Kubernetes handles the relaunch process as well.
Upload code on Container Registry
If you have used Cloud Run before, you are aware of how we build and push docker files into the Container Registry. I am not going to dive deep into the details, but I will say that I am using Cloud Build connected to Github. So, every time there is a file related to a Cloud Run job changed on the Master branch, the whole Cloud Run job is redeployed.
For the docker file that I am using for K8s, it follows the same logic up to pushing it into the Container Registry. Afterwards, I just take the ID of the docker. Here is an example of a cloudbuild.yaml that is triggered based on modifications:
cloudbuild.yaml
Once it is deployed, I will be able to find a generated build in the Container Registry.

Deploy Docker containers on K8s
Now, we are ready for the final part. The K8s Cluster is running, and the script is modified and uploaded on the Container Registry. To do anything related to GKE and K8s, we have to open a Cloud Shell console and connect to GKE.

Only 6 commands to execute:
Example:
You are inside your GKE and ready to deploy. When you deploy a docker container, in K8s terminology it is called a "Pod".
The best practice while deploying is to create a namespace and to have a set of instructions saved as a .yaml file.
A namespace is a kink of additional labelling for a set of docker containers. I suggest you always use namespaces so that inside one cluster, you are able to filter through docker containers deployed for different use cases.
To create a namespace
Here is an example of deployment.yaml instruction to deploy docker containers.
deployment.yaml
- Desired number of simultaneously running docker containers
- ID of your docker container in the Cloud Registry
- Given configuration for each docker container
- Max of a given configuration. If exceeds, the container will fail and be relaunched automatically
- Global environmental variables used in Main.py script
Once, the configuration file is settled, here is the command I use to run the deployment:
You can always save a file in .yaml and run the cat command by mentioning the name of the file.
Some other useful commands:
Conclusion
In this article, I wanted to reunite both the theoretical and technical aspects. The goal was to inform you that it is possible to reduce your architectural costs and give you a concrete guide on how to do it.
We succeeded in cutting our costs because of the following prerequisites:
- Our jobs were already run on Docker containers. So, to pass to Kubernetes, almost no additional development was needed.
- Our article extraction jobs were too heavy for Cloud Run, and the number of invocations was significant. Kubernetes helped to reduce costs. However, if you have Cloud Run jobs with 1,000 invocations a day, Kubernetes is not a cost-saving solution.
Our method also requires a basic understanding of Kubernetes. It is not hard to learn, but you will need some time to adjust.
I hope this article will help someone with their struggles. Best of luck to you!





























