> ## Documentation Index
> Fetch the complete documentation index at: https://newscatcherinc-docs.mintlify.site/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Articles deduplication
> How News API identifies and filters near-identical articles, and how to use deduplication in your queries.
When a major story breaks, hundreds of outlets publish articles covering the
same event — often with nearly identical content. News API's deduplication
feature identifies these near-identical articles and returns only the most
authoritative version, giving you a cleaner, more diverse result set.
You can use deduplication on the `/search` endpoint via the
[`exclude_duplicates`](/news-api/api-reference/search/search-articles-post#body-exclude-duplicates)
parameter.
## How deduplication works
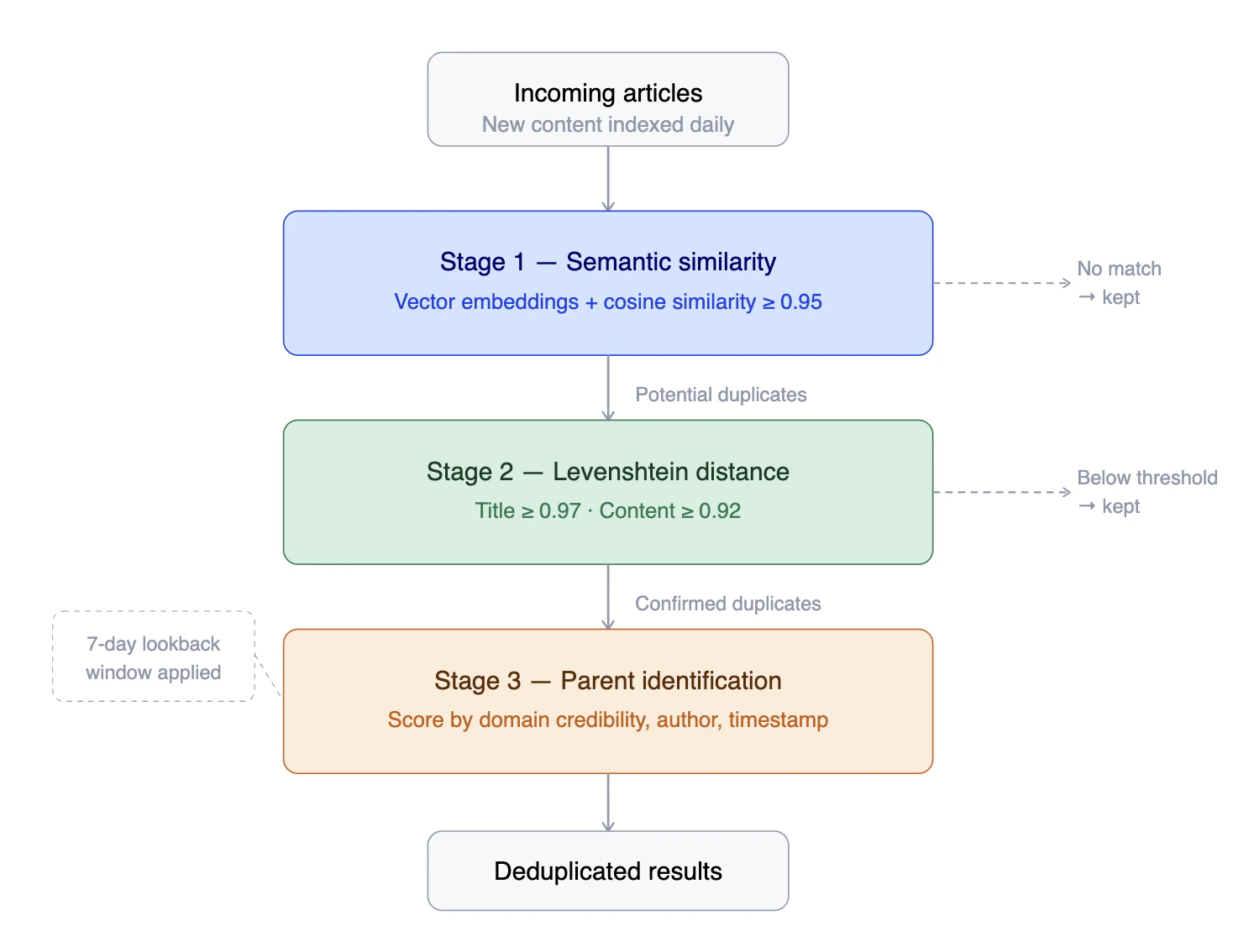 Deduplication runs as a three-stage pipeline applied to each batch of indexed
articles.
### Stage 1 — Semantic similarity
Each article is converted into a vector embedding using the NLP pipeline. News
API then computes cosine similarity between article embeddings, flagging pairs
that exceed a threshold of **0.95** as potential duplicates.
This stage catches articles that cover the same event in different words —
rewrites, syndicated content, and articles from different sources reporting on
the same facts.
### Stage 2 — Levenshtein distance
Potential duplicates from Stage 1 are re-evaluated using Levenshtein distance —
the minimum number of single-character edits required to transform one text into
another. Two thresholds apply:
* **0.97** for article titles
* **0.92** for article content
This refinement reduces false positives: articles that discuss similar topics
differently are distinguished from true near-copies.
### Stage 3 — Parent identification
When a group of duplicates is identified, News API selects the most
authoritative article as the "parent" using a scoring algorithm that considers
domain credibility, author reputation, and publication timestamp. The parent
article is returned in results; duplicates are suppressed.
Parent status can change if a newly discovered duplicate scores higher on the
credibility algorithm.
### Lookback window
Each new article is compared against articles indexed in the **past seven
days**. This ensures that duplicates published days after the original — delayed
reporting, republished content — are still caught.
## Enable deduplication in search requests
Set `exclude_duplicates` to `true` in a `/search` request to suppress duplicate
articles:
```bash cURL theme={null}
curl -X POST "https://v3-api.newscatcherapi.com/api/search" \
-H "x-api-token: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"q": "market value",
"lang": "en",
"theme": "Finance",
"exclude_duplicates": true
}'
```
```python Python theme={null}
from newscatcher import NewscatcherApi
client = NewscatcherApi(api_key="YOUR_API_KEY")
response = client.search.post(
q="market value",
lang="en",
theme="Finance",
exclude_duplicates=True,
)
for article in response.articles:
print(f"{article.duplicate_count} duplicates — {article.title}")
```
```typescript TypeScript theme={null}
import { NewscatcherApiClient } from "newscatcher-sdk";
const client = new NewscatcherApiClient({ apiKey: "YOUR_API_KEY" });
const response = await client.search.post({
q: "market value",
lang: "en",
theme: "Finance",
excludeDuplicates: true,
});
response.articles?.forEach((article) => {
console.log(`${article.duplicateCount} duplicates — ${article.title}`);
});
```
```java Java theme={null}
import com.newscatcher.api.NewscatcherApiClient;
import com.newscatcher.api.resources.search.requests.PostSearchRequest;
NewscatcherApiClient client = NewscatcherApiClient.builder()
.apiKey("YOUR_API_KEY")
.build();
var response = client.search().post(
PostSearchRequest.builder()
.q("market value")
.lang("en")
.theme("Finance")
.excludeDuplicates(true)
.build()
);
response.getArticles().forEach(article ->
System.out.println(article.getDuplicateCount() + " duplicates — " + article.getTitle())
);
```
### Response fields
When `exclude_duplicates` is `true`, each article in the response includes two
additional fields:
| Field | Description |
| ----------------------------- | ---------------------------------------------------------------------------------------------- |
| `duplicate_count` | Number of duplicate articles suppressed for this result. |
| `duplicate_articles_group_id` | Unique identifier for the duplicate group. Use this to cross-reference groups across requests. |
## Deduplication vs clustering
Both features help manage large volumes of articles, but serve different
purposes:
| | Deduplication | Clustering |
| ------------------------ | ------------------------------- | ------------------------------------- |
| **Purpose** | Removes near-identical articles | Groups related articles |
| **Output** | Unique articles only | All articles, organized into groups |
| **Similarity threshold** | High (near-exact matches) | Lower (topically related) |
| **Article count** | Reduced | Unchanged |
| **Best for** | Clean feeds, unique content | Multi-source coverage, trend analysis |
For clustering details, see
[Clustering news articles](/news-api/guides-and-concepts/clustering-news-articles).
## See also
* [Clustering news articles](/news-api/guides-and-concepts/clustering-news-articles)
* [Search endpoint reference](/news-api/api-reference/search/search-articles-post)
* [NLP features](/news-api/guides-and-concepts/nlp-features)
Deduplication runs as a three-stage pipeline applied to each batch of indexed
articles.
### Stage 1 — Semantic similarity
Each article is converted into a vector embedding using the NLP pipeline. News
API then computes cosine similarity between article embeddings, flagging pairs
that exceed a threshold of **0.95** as potential duplicates.
This stage catches articles that cover the same event in different words —
rewrites, syndicated content, and articles from different sources reporting on
the same facts.
### Stage 2 — Levenshtein distance
Potential duplicates from Stage 1 are re-evaluated using Levenshtein distance —
the minimum number of single-character edits required to transform one text into
another. Two thresholds apply:
* **0.97** for article titles
* **0.92** for article content
This refinement reduces false positives: articles that discuss similar topics
differently are distinguished from true near-copies.
### Stage 3 — Parent identification
When a group of duplicates is identified, News API selects the most
authoritative article as the "parent" using a scoring algorithm that considers
domain credibility, author reputation, and publication timestamp. The parent
article is returned in results; duplicates are suppressed.
Parent status can change if a newly discovered duplicate scores higher on the
credibility algorithm.
### Lookback window
Each new article is compared against articles indexed in the **past seven
days**. This ensures that duplicates published days after the original — delayed
reporting, republished content — are still caught.
## Enable deduplication in search requests
Set `exclude_duplicates` to `true` in a `/search` request to suppress duplicate
articles:
```bash cURL theme={null}
curl -X POST "https://v3-api.newscatcherapi.com/api/search" \
-H "x-api-token: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"q": "market value",
"lang": "en",
"theme": "Finance",
"exclude_duplicates": true
}'
```
```python Python theme={null}
from newscatcher import NewscatcherApi
client = NewscatcherApi(api_key="YOUR_API_KEY")
response = client.search.post(
q="market value",
lang="en",
theme="Finance",
exclude_duplicates=True,
)
for article in response.articles:
print(f"{article.duplicate_count} duplicates — {article.title}")
```
```typescript TypeScript theme={null}
import { NewscatcherApiClient } from "newscatcher-sdk";
const client = new NewscatcherApiClient({ apiKey: "YOUR_API_KEY" });
const response = await client.search.post({
q: "market value",
lang: "en",
theme: "Finance",
excludeDuplicates: true,
});
response.articles?.forEach((article) => {
console.log(`${article.duplicateCount} duplicates — ${article.title}`);
});
```
```java Java theme={null}
import com.newscatcher.api.NewscatcherApiClient;
import com.newscatcher.api.resources.search.requests.PostSearchRequest;
NewscatcherApiClient client = NewscatcherApiClient.builder()
.apiKey("YOUR_API_KEY")
.build();
var response = client.search().post(
PostSearchRequest.builder()
.q("market value")
.lang("en")
.theme("Finance")
.excludeDuplicates(true)
.build()
);
response.getArticles().forEach(article ->
System.out.println(article.getDuplicateCount() + " duplicates — " + article.getTitle())
);
```
### Response fields
When `exclude_duplicates` is `true`, each article in the response includes two
additional fields:
| Field | Description |
| ----------------------------- | ---------------------------------------------------------------------------------------------- |
| `duplicate_count` | Number of duplicate articles suppressed for this result. |
| `duplicate_articles_group_id` | Unique identifier for the duplicate group. Use this to cross-reference groups across requests. |
## Deduplication vs clustering
Both features help manage large volumes of articles, but serve different
purposes:
| | Deduplication | Clustering |
| ------------------------ | ------------------------------- | ------------------------------------- |
| **Purpose** | Removes near-identical articles | Groups related articles |
| **Output** | Unique articles only | All articles, organized into groups |
| **Similarity threshold** | High (near-exact matches) | Lower (topically related) |
| **Article count** | Reduced | Unchanged |
| **Best for** | Clean feeds, unique content | Multi-source coverage, trend analysis |
For clustering details, see
[Clustering news articles](/news-api/guides-and-concepts/clustering-news-articles).
## See also
* [Clustering news articles](/news-api/guides-and-concepts/clustering-news-articles)
* [Search endpoint reference](/news-api/api-reference/search/search-articles-post)
* [NLP features](/news-api/guides-and-concepts/nlp-features)